



Einführung
In Navigator arbeiten AI-Lösungen auf zwei Ebenen:
- Service Layer – API-Methoden, die für bestimmte Implementierungsaufgaben aufgerufen werden können
- Implementierungsschicht im Navigator-System – spezifische Systemfunktionen mit AI-Diensten in bestimmten Bereichen
Maschinelles Lernen wurde für Windows 10 und Linux implementiert.
AI-Dienste
AI-Dienste werden in der Containerarchitektur verfügbar gemacht. Eine bestimmte Gruppe von Diensten, die miteinander kooperieren können, wird im sogenannten Docker geschlossen – einem tragbaren virtuellen Container, der auf einem Linux-Server ausgeführt werden kann. Die Docker-Installation ist schnell und einfach. Die Dienste arbeiten in der Infrastruktur des Kunden und erfordern keinen Datenaustausch außerhalb (in der Cloud).
OCR
Der Zweck der OCR (optische Zeichenerkennung) besteht darin, Text oder eine durchsuchbare PDFA aus einem hochgeladenen Foto oder einer PDF-Datei zu generieren.
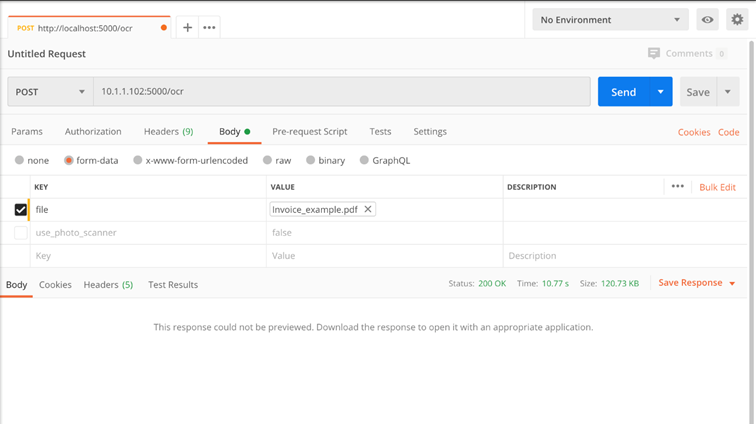
Methode: ./ocr
Eingabeparameter:
- file – Datei jpg/jpeg, png, tif, pdf
- use_photo_scanner – standardmäßig true. Beim Laden eines Fotos eines mit einem Smartphone aufgenommenen Dokuments wendet das System eine Reihe von Filtern an (Erhöhung des Kontrasts, Entfernen von Schatten usw.), die die Wirksamkeit der OCR erhöhen
Kehrt zurück:
· file – PDFA-Datei (durchsuchbares PDF)
Beispiel:
Textklassifizierung
Der Zweck dieser Gruppe von Diensten besteht darin, eine Klasse (Dokumenttyp, Kategorie, Eigentümer, Kontonummer usw.) basierend auf der Analyse des Textes auf dem Dokument zu bestimmen.
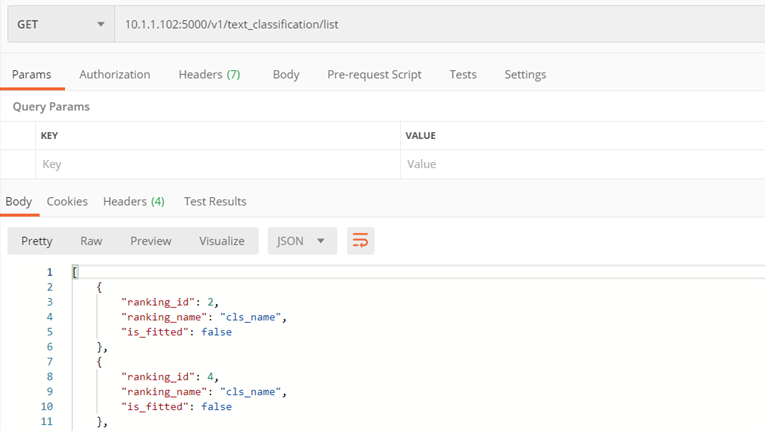
Methode ./v1/text_classification/list
Der Zweck der Methode besteht darin, eine Liste der auf dem Server gespeicherten Klassifizierer zurückzugeben
Eingabeparameter :
- keiner
Kehrt zurück:
- Liste der verfügbaren Klassifikatoren, einschließlich
- ranking_id – Klassifikator-ID,
- ranking_name – Klassifizierername,
- is_fitted – ob gelernt wird
Beispiel:
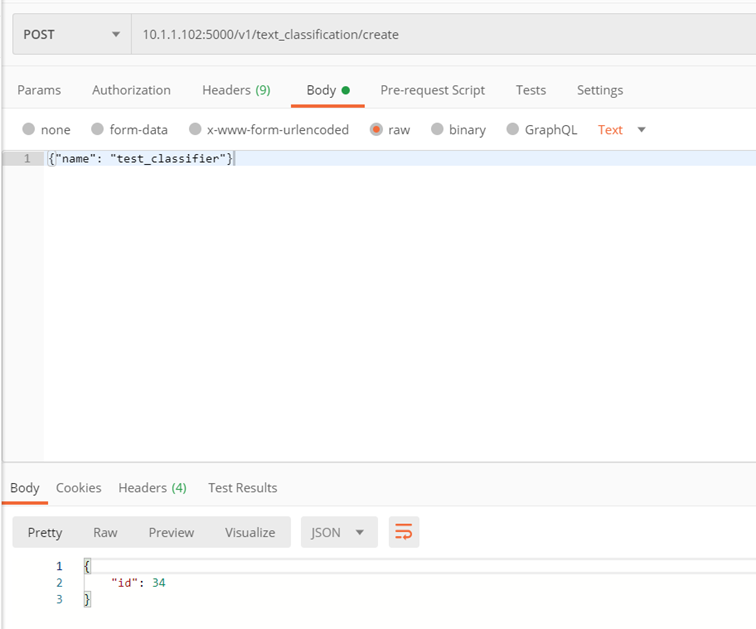
Methode: ./v1/text_classification/create
Der Zweck der Methode besteht darin, einen Klassifikator zu erstellen.
Eingabeparameter:
- name – Klassifikatorname
Kehrt zurück:
- classifer_id – ID des erstellten Klassifikators
Beispiel:
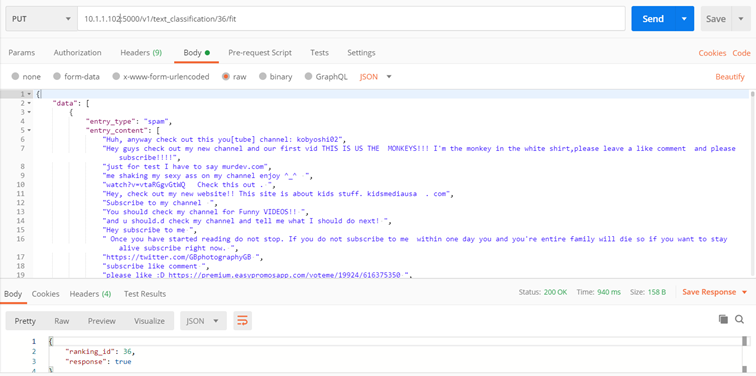
Methode: ./v1/text_classification/{classifier_id}/fit
Der Zweck der Methode besteht darin, den Klassifikator zu trainieren
Eingabeparameter:
- classifier_id – Klassifikator-ID
- collection (Sammlung von Lerntexten)
- entry_type – Klassenname (z. B. Rechnung, Lebenslauf, Brief usw.)
- entry_content – Textblock (vollständiger Dokumentinhalt, alles, was OCR zurückgibt)
Kehrt zurück:
- code 200 – positives Lernen des Modells
- code 422 – Fehler (eine Fehlermeldung wird zurückgegeben)
Beispiel:
Methode: ./v1/text_classification/{classifier_id}/remove
Der Zweck der Methode besteht darin, den Klassifikator zu entfernen
Eingabeparameter:
- classifier_id – iID des Klassifikators, den wir vom Server entfernen möchten
Kehrt zurück:
- code 200 – Positive Modelllöschung
- code 422 – Fehler (eine Fehlermeldung wird zurückgegeben)
Beispiel:
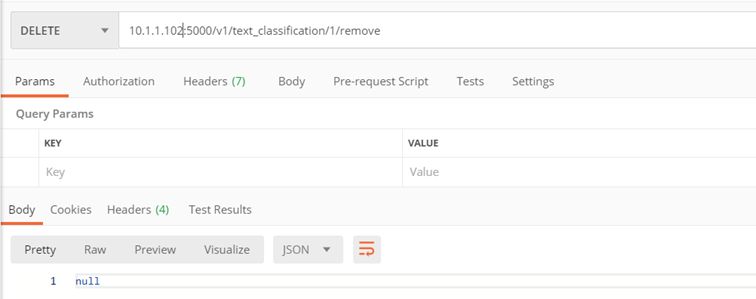
Methode: ./v1/text_classification/{classifier_id}/predict
Der Zweck der Methode besteht darin, eine Textklassifizierung für einen bestimmten Klassifizierer durchzuführen
Eingabeparameter:
- classifier_id– Klassifikators, auf dessen Grundlage die Klassifizierung durchgeführt werden soll
- text – Der zu klassifizierende Text
- file – Die zu klassifizierende PDFA-Datei
Bemerkungen :
Es kann entweder eine Datei oder ein Text angegeben werden.
Kehrt zurück:
- Sammlung von Klassen mit Wahrscheinlichkeitsrang für den übergebenen Text:
- pred_proba – Wahrscheinlichkeit
- type_id – Klasse
- rank – Position im Ranking
Beispiel:
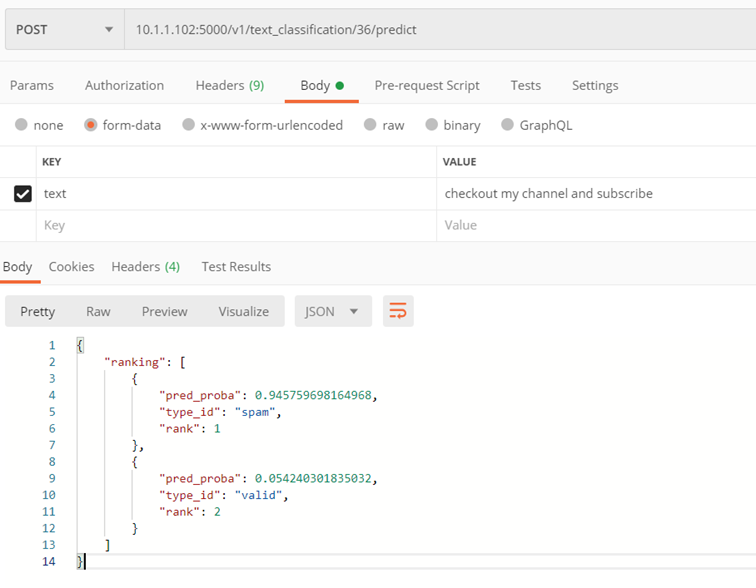
Datenerfassung
Der Zweck dieser Gruppe von Diensten besteht darin, Daten aus dem untersuchten Dokument zu erfassen. Bei Rechnungen sind dies beispielsweise: Rechnungsnummer, Steueridentifikationsnummern, Daten, Kontonummer, Sätze und Mehrwertsteuerbeträge, Tabelle mit Belegpositionen
Methode ./v1/data_capture/general/list
Gibt die derzeit verfügbaren generischen Modelle zurück
Eingabeparameter:
- keiner
Kehrt zurück:
- Liste der verfügbaren generischen Modelle mit ihrer ID
Beispiel:
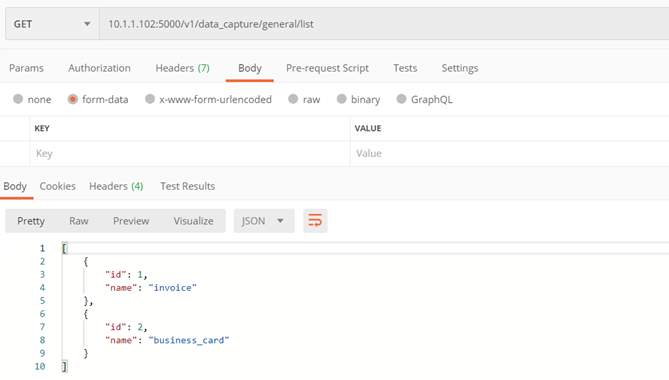
Methode ./v1/data_capture/general/{model_id}/locale/list
Der Zweck der Methode besteht darin, die unterstützten Sprachen und die darin verfügbaren Präfixe zurückzugeben
Methode nur für das allgemeine Rechnungsmodell – Nr. 1
Eingabeparameter:
- model_id – ID des Modells, dessen Präfixe von der Methode zurückgegeben werden
Kehrt zurück:
- Liste der Wörterbücher mit Informationen zu den unterstützten Sprachen und den darin verfügbaren Präfixen
Beispiel:
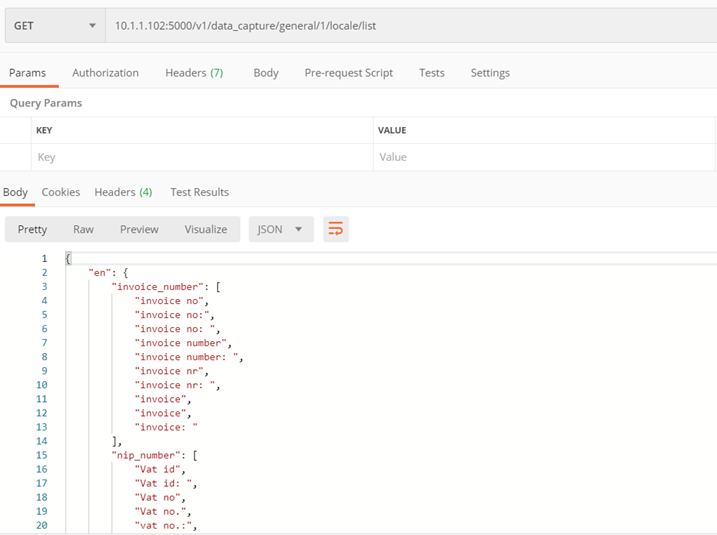
Methode ./v1/data_capture/general/1/locale/upload
Sie können Ihre eigene unterstützte Sprache hinzufügen, indem Sie Präfixe eingeben
Methode nur für das allgemeine Rechnungsmodell – Nr. 1
Parametrie:
- locale_name – Der Name des lokalen (Sprache), dessen Präfixe wir übergeben möchten, muss eines der folgenden sein:
af, ar, bg, bn, ca, cs, cy, da, de, el, en, es, et, fa, fi, fr, gu, he, hi, hr, hu, id, it, ja, kn, ko, lt, lv, mk, ml, mr, ne, nl, no, pa, pl, pt, ro, ru, sk, sl, so, sq, sv, sw, ta, te, th, tl, tr, uk, ur, vi, zh-cn, zh-tw
- prefixes_json – Ein Wörterbuch, das für jeden der Schlüssel (Rechnungsnummer, NIP-Nummer, Auftrags- und Steuern (vat_rates), Rechnungsdatum, Zahlungsdatum, Verkaufsdatum) eine Liste von Präfixen in einer bestimmten Sprache enthält
Kehrt zurück:
- Code 200 – positives Lernen des Modells
- Code 400 – Fehler
Beispiel:
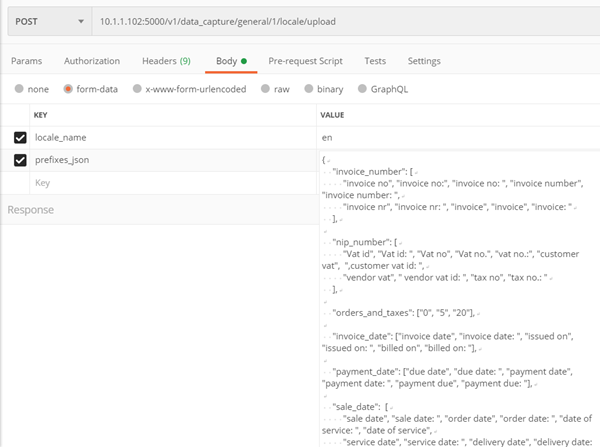
Methode ./v1/data_capture/general/{model_id}/locale/{locale_name}/remove
Unterstützte Sprachentfernung
Methode nur für das allgemeine Rechnungsmodell – Nr. 1
Eingabeparameter:
- locale_name – Name der zu entfernenden Sprache, z. ‘En’
- model_id – Modell-ID, aus der das Gebietsschema entfernt wird
Kehrt zurück:
- Code 200 – erfolgreiche Entfernung
Beispiel:
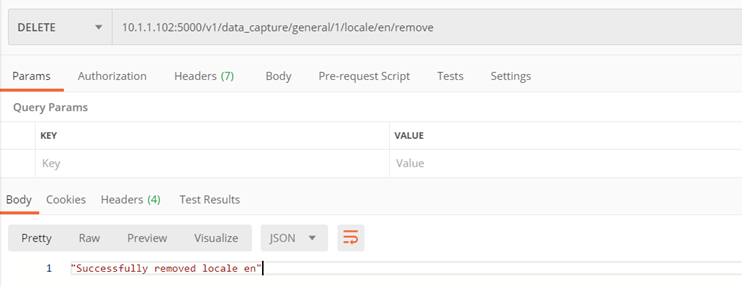
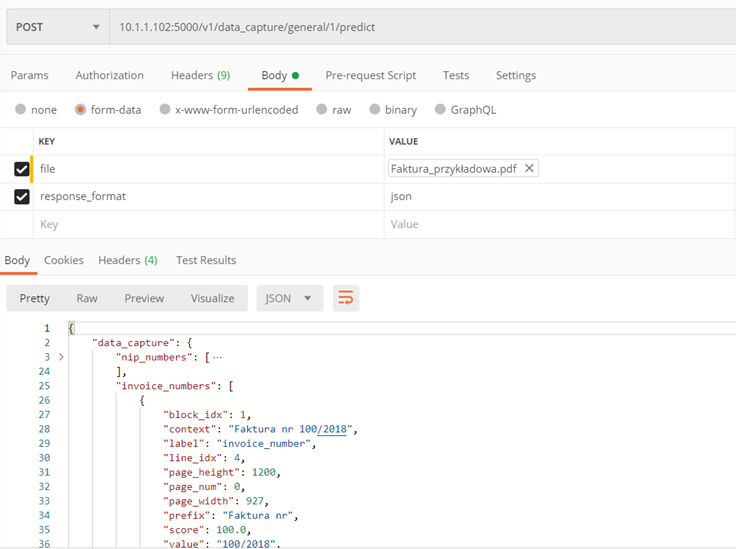
Methode ./v1/data_capture/general/{model_id}/predict
Geben Sie die im Text der hochgeladenen Datei enthaltenen Informationen zurück.
Eingabeparameter:
- model_id – Modell-ID, mit der wir die Vorhersage durchführen
- file – durchsuchbare PDF-Datei
- locale (optional) – Name der Dokumentensprache. Wenn nicht angegeben, bestimmt das Programm die Sprache aus dem Text selbst und verwendet die entsprechenden Präfixe
- response_format (optional) – Das Format, in dem die Informationen zurückgegeben werden, zur Auswahl: none, xml, json
Kehrt zurück:
- Informationen aus dem Text im JSON- oder XML-Format
Beispiel:
Dateisplitter
Ein Dienst, der gescannte Dokumente in einer Datei in separate Dateien aufteilt, wobei jede Datei ein separates Dokument darstellt. Es hat die Fähigkeit, eine beliebige Anzahl von eigenen Splittern für Ihre eigene Art von Dokumenten zu unterrichten
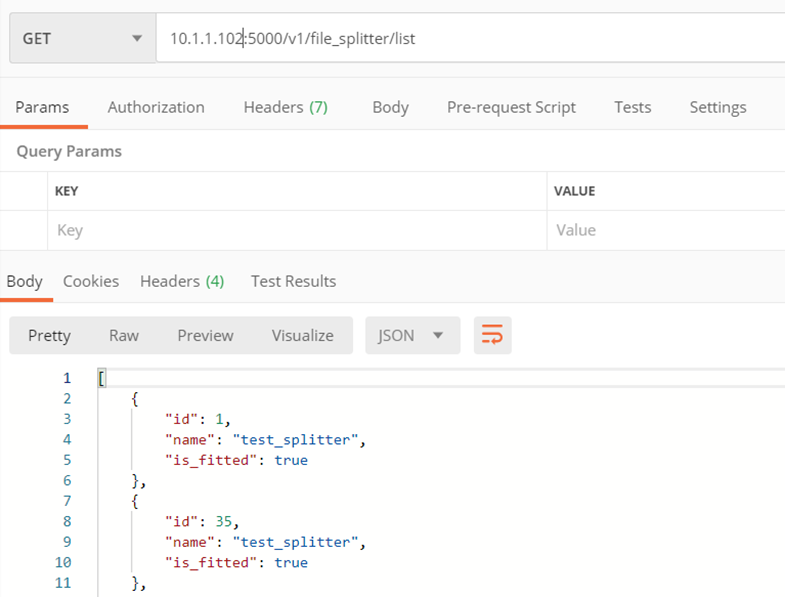
Methode ./v1/file_splitter/list
Gibt eine Liste der Splitter (Modelle) zurück.
Eingabeparameter:
- keiner
Kehrt zurück:
- Eine Liste der verfügbaren Splitter, die jeweils Namen, ID und Informationen darüber enthält, ob sie gelernt wurden
Beispiel:
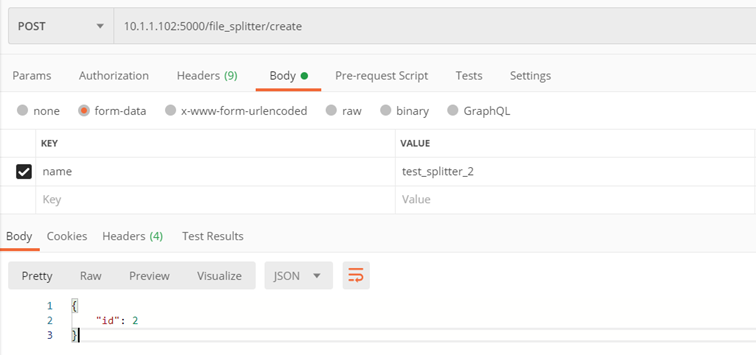
Methode ./v1/file_splitter/create
Erstellen Sie Ihren eigenen Splitter
Input parameters:
- name – Splittername
Kehrt zurück:
- Splitter-ID erstellt
Beispiel:
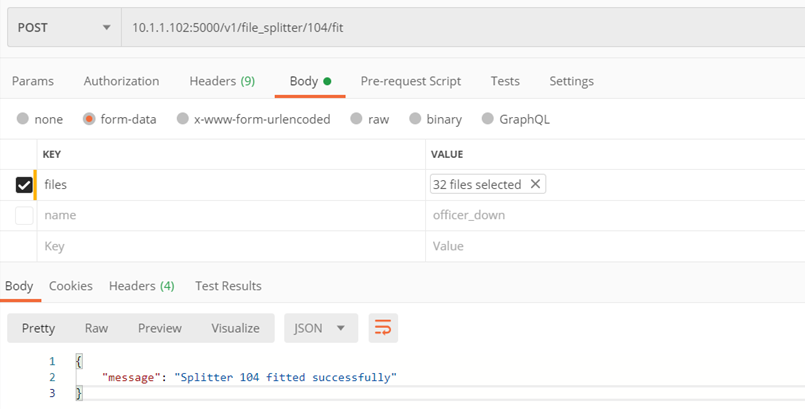
Methode ./v1/file_splitter/{splitter_id}/fit
Unterrichten eines Dokumentensplitters
Eingabeparameter:
- splitter_id – ID des Splitters, den wir lernen möchten
- files – Eine Liste von Dateien, auf deren Grundlage der Splitter das Teilen von Dokumenten lernt
Kehrt zurück:
- Code 200 – korrekt gelernter Splitter
- Code 400 – Fehler
Beispiel:
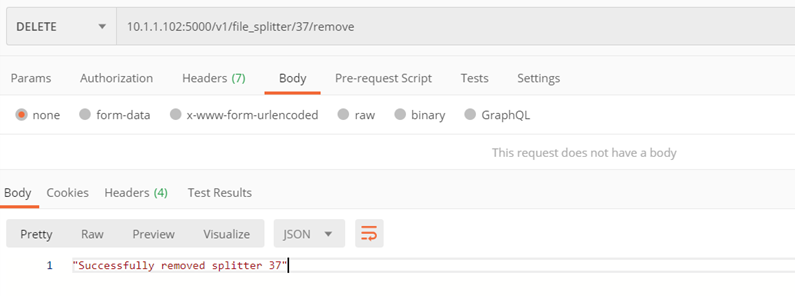
Methode ./v1/file_splitter/{splitter_id}/remove
Entfernen des ausgewählten Splitters
Eingabeparameter:
- splitter_id – ID des zu entfernenden Splitters
Kehrt zurück:
- Code 200 – positive Entfernung
- Code 400 – Fehler
Beispiel:
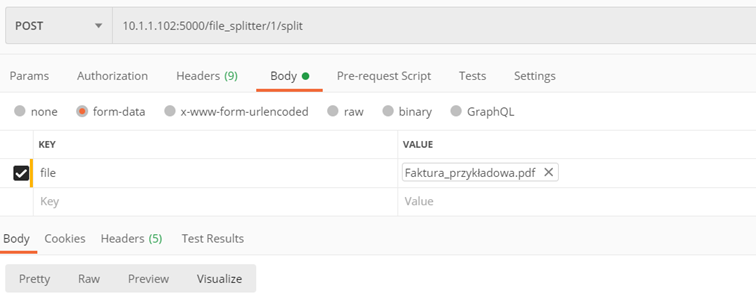
Methode ./v1/file_splitter/{splitter_id}/split
Teilen Sie eine Datei mit mehreren Dokumenten in einzelne auf
Eingabeparameter:
- splitter_id – ID des Splitters, den wir zum Teilen der Datei verwenden
- file – Die durchsuchbare PDF-Datei, die wir teilen möchten
Kehrt zurück:
- Zip-Datei mit gespeicherten separaten PDF-Dateien
Beispiel:
Implementierung von AI-Diensten in Navigator
Um mit dem AI-Dienst arbeiten zu können, müssen Sie einige Änderungen vornehmen, darunter die Datenbank und den Navigator. Zuerst müssen Sie die Einstellungen in der Basis eingeben, und dann können Sie zu den Einstellungen im System gehen.
Datenbankeinstellungen
Aktivieren Sie den AI-Dienst
Damit AI-Dienste aktiv sind, muss die richtige AI-Serveradresse in die Systemdatenbank in der Einstellungstabelle [Sg] eingegeben werden. Um zu überprüfen, welche Adresse aktuell eingestellt ist, geben Sie den folgenden Befehl ein: SELECT * FROM Sg WHERE Code = ‚Address_AI_API‘ und führen Sie ihn aus.
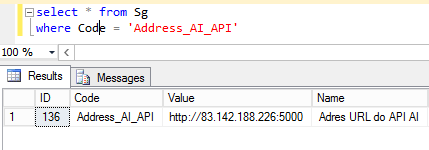
Geben Sie den folgenden Befehl ein, um den in der Spalte Wert angezeigten Wert zu aktualisieren:
UPDATE Sg SET Value = ‚Value of the new address‘ WHERE Code = ‚Address_AI_API‘ und führen Sie es aus.
Bestimmen des Trainingssatzes
Der Schulungssatz ist der Satz von Dokumenten, auf deren Grundlage der Dienst gelernt wird. Auf Datenbankebene können Sie festlegen, wie viele Dokumente im Trainingssatz enthalten sein sollen. Geben Sie den Befehl ein, um die Menge zu überprüfen: SELECT * FROM Sg WHERE Code = ‚MaxFilesPerType‘. Standardmäßig ist dieser Wert 50.

Geben Sie den folgenden Befehl ein, um den in der Spalte Value angezeigten Wert zu aktualisieren:
UPDATE Sg SET Value = ‘Anzahl der Dokumente’ WHERE Code = ‘MaxFilesPerType’ and execute it.
Automatische Modellaktualisierung
Alle Modelle werden so eingestellt, dass sie jeden Tag automatisch aktualisiert werden, wenn Sie sich zum ersten Mal beim System anmelden. Ändern Sie den Wert in der Tabelle [Sg], um die automatische Aktualisierung zu deaktivieren / aktivieren. Überprüfen Sie, ob die automatische Aktualisierung aktiviert ist, indem Sie den folgenden Befehl eingeben: SELECT * FROM Sg WHERE Code = ‚RecommedationAutoRefreshModel‘

Die Spalte Value enthält den Wert, der für die automatische Aktualisierung verantwortlich ist.
- 0 – deaktiviert
- 1 – aktiviert
Geben Sie den folgenden Befehl ein, um den in der Spalte Vert angezeigten Wert zu aktualisieren:
UPDATE Sg SET Value = ’0 oder 1’ WHERE Code = ‘RecommedationAutoRefreshModel’ und führen Sie es aus.
Systemeinstellungen
Empfehlungen zu den Formularfeldern
Der AI Text-Klassifizierungsdienst wird verwendet, um Werte in ausgewählten Feldern des Formulars zu empfehlen. Das erlernte Modell wird im Anhang-OCR-Prozess ausgeführt. Nach Abschluss der OCR-Arbeit hat dieser Feld folgende Auswirkungen:
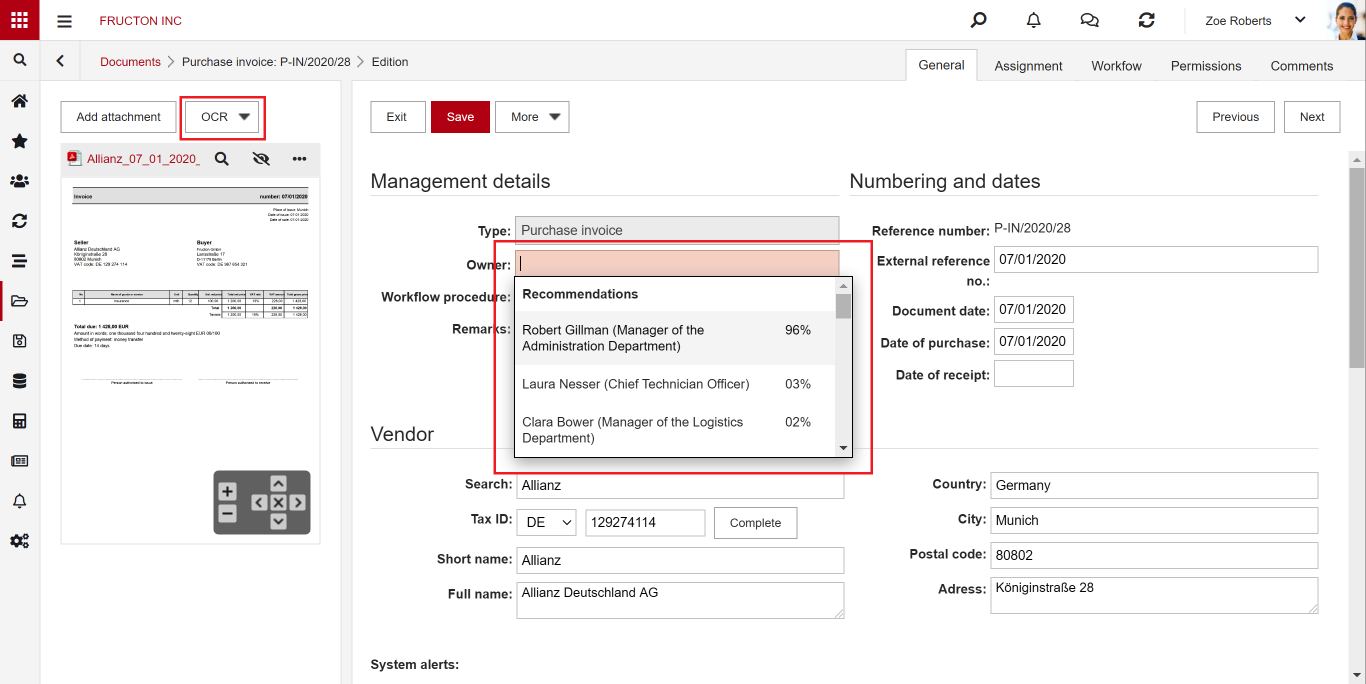
Erstellen Sie das Modell
Um ein Modell für ein bestimmtes Feld zu erstellen, wählen Sie Empfehlungen anzeigen.
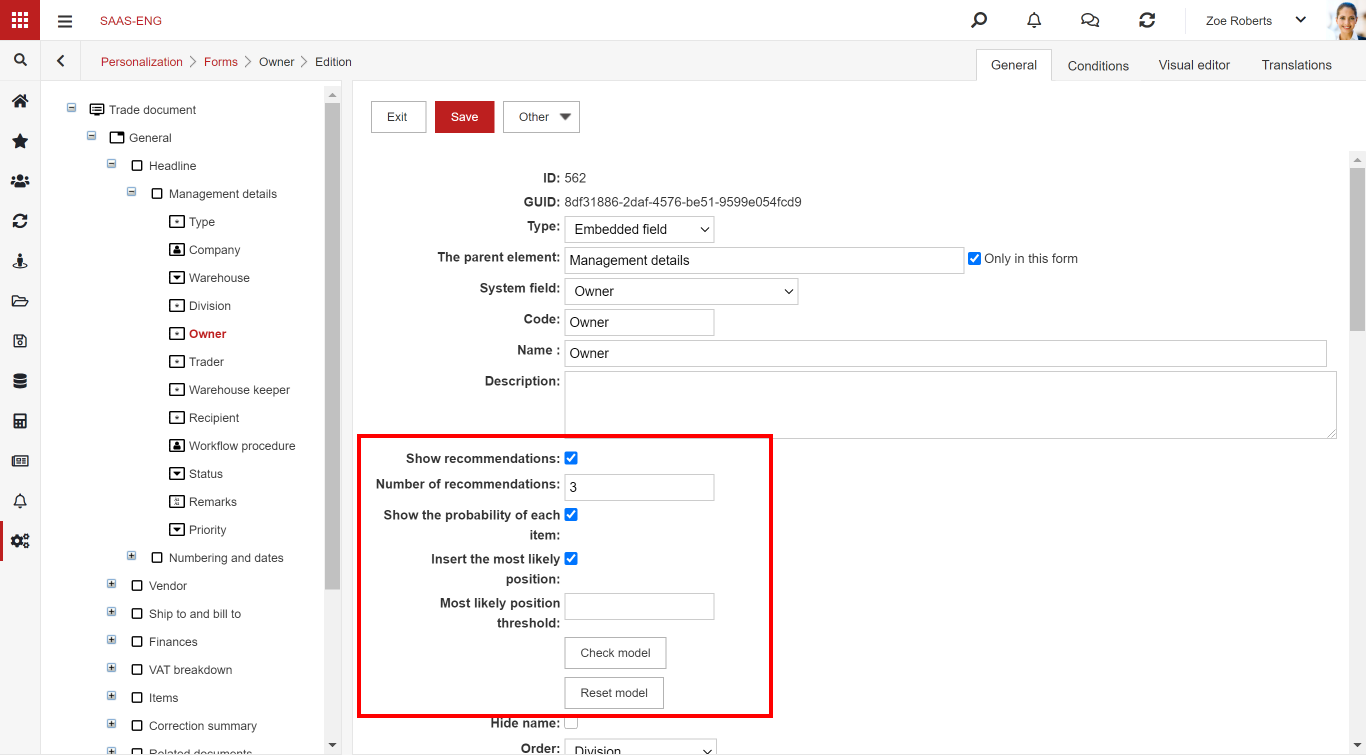
Derzeit ist die Option für die Systemfelder verfügbar: Auftragnehmer, Auftragnehmer – Bearbeiten, Eigentümer, Firma, Kategorie, Typ und Attribut für den Typ der automatischen Suche.
Nach dem Klicken auf „Speichern“ wird das Modell trainiert (im Hintergrund). Es dauert ca. 20 Sekunden. Nach dieser Zeit, nachdem der OCR-Prozess abgeschlossen ist, sollten Empfehlungen in diesem Feld im Dokument erscheinen. Wenn sie nicht angezeigt werden, warten Sie lange (ca. 10 Minuten). Möglicherweise ist der Trainingsprozess länger (z. B. aufgrund eines größeren Trainingssatzes oder der Serverlast).
Wichtig:
- Das Modell funktioniert, wenn eine ausreichende Anzahl korrekt eingegebener Dokumente in der Datenbank vorhanden ist. Es ist am besten, mehr als 20 Beispiele für jede Klasse bereitzustellen (z. B. 20 Dokumente mit vollständigem Eigentümer).
- Idealerweise sollte die Verteilung in jeder Klasse ausgeglichen sein (z. B. Rechnungen, die verschiedenen Eigentümern zugewiesen wurden).
- Das Business Navigator-System lädt nur die neuesten Daten für den Lernprozess herunter. Es werden nur Dokumente mit OCR-verknüpften Anhängen (Daten in [OcrText] in Tabelle [Fi]) berücksichtigt.
- Das Modell wird auf dem AI-Serviceserver unter dem Namen CodeCompany_FieldType_FieldID (z. B. FRUCTON_FlSy_5, FRUCTON_FL_8660) gespeichert, wobei:
- CompanyCode – CompanyCode aus der Tabelle [Sg]
- FieldType – FlSy für Systemfelder, Fl für Attribute oder Di für Wörterbücher
- FieldID – ID aus der FlSy-, Fl- oder Di-Tabelle
- Es ist nicht möglich, ein Modell aus Business Navigator vom AI-Server zu löschen. Um die Verwendung zu beenden, deaktivieren Sie einfach das Kontrollkästchen Empfehlungen anzeigen. Verwenden Sie die API, um das Modell vom AI-Server zu entfernen.
- Um das Modell zu aktualisieren, klicken Sie auf „Modell zurücksetzen“ (das Modell wird gelöscht und der Lernprozess beginnt erneut).
OCR BN
Unter dem Namen der OCR-Engine steht „BN“ für eine Reihe von AI-Diensten: OCR, Textklassifizierung, Datenerfassung. Darüber hinaus führt das System andere Automatisierungsprozesse durch (z. B. Laden eines Modelldokuments, Herunterladen von Auftragnehmerdaten vom Statistischen Zentralamt usw.)
Wir wählen die Engine für einen bestimmten Dokumenttyp.
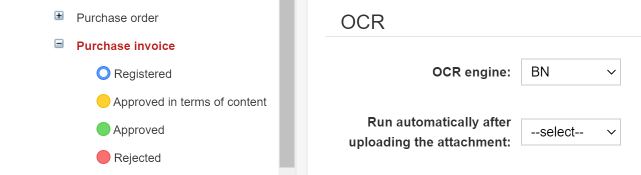
Schritte im OCR-Prozess, die vom BN-Motor ausgeführt werden:
- OCR
- Wenn der Anhang keinen Text enthält (keine durchsuchbare PDF-Datei oder keine zuvor OCR-Datei), wird er an API AI (/ ocr) gesendet.
- Der zurückgegebene durchsuchbare PDFA wird in der Navigator-Datenbank in der Tabelle „Fi“ in der Spalte „PdfFile“ gespeichert.
- Datenerfassung
- Die PDFA-Datei wird an den API-AI-Prozess gesendet (./data_capture/general/1/predict). Die API gibt die XML-Datei und den Klartext der Datei zurück.
- Klartext wird in der Navigator-Datenbank in der Tabelle „Fi“ in der Spalte „OcrText“ gespeichert
- Die XML-Datei wird in der Navigator-Datenbank in der Tabelle „Fi“ in der Spalte „OcrData“ gespeichert
- Textklassifizierung
- Klartext wird an den API-AI-Prozess „Textklassifizierung“ gesendet (/ text_classification / {classifier_id} / Predict). Der Prozess wird für alle Modelle ausgeführt, die in allen Formen des Bereichs „Dokumente“ definiert sind
- Entscheidung, welches Unternehmen, Art des Dokuments, Kategorie:
- Beim Aufrufen von OCR über „Add Multiple from OCR“ verwendet die Engine die Kategorie und den Typ, die aus dem Kontext des Aufrufs bekannt sind. Auch wenn die Textklassifizierung eine andere Empfehlung für diese Felder zurückgegeben hat, wird diese nicht berücksichtigt
- In ähnlicher Weise wird es für das ausgewählte Unternehmen unabhängig von der Angabe der Textklassifizierung auch für das Dokument festgelegt
- Wenn der „AI-Hot-Ordner“ verwendet wird, ermittelt das System den Typ, die Kategorie und das Unternehmen anhand der höchsten empfohlenen Textklassifizierungsangabe. Warnung! Jedes dieser Felder muss in mindestens einem Formular mit „Höchstwahrscheinliche Position einfügen“ gekennzeichnet sein.
- Einstellung des Auftragnehmers
- Die Datenerfassung gibt 2 NIPs zurück (Felder VATID und VATID1). Der Auftragnehmer ist derjenige, der nicht „unser Unternehmen“ ist, dh keinem der Unternehmen zugeordnet ist (Einstellungen -> Dateien -> Unternehmen -> Bearbeiten -> Auftragnehmer).
- Befindet sich in der Auftragnehmerdatei ein Auftragnehmer mit dieser Steueridentifikationsnummer, wird diese in das Formular eingefügt
- Wenn die Auftragnehmerdatei keinen Auftragnehmer mit dieser NIP-Nummer enthält, wird sie aus der Datenbank des Statistischen Zentralamtes geladen
- Füllen Sie unvollendete Auswahlfelder basierend auf der Empfehlung zur Textklassifizierung aus
- Ausfüllen der leeren Felder basierend auf der Datenerfassungsdatei (Spalte „OcrData“ in der Tabelle „Fi“)
- Wenn der Auftragnehmer für den ausgewählten Dokumenttyp über das detaillierte Datenerfassungsmodell verfügt, wird der AI-Dienst gestartet ./data_capture/templates///template_idarzenia/predict. Die Felder, die bisher nicht ausgefüllt wurden, werden mit den von diesem Service zurückgegebenen Werten ausgefüllt.
- Füllen Sie die restlichen leeren Felder auf der Grundlage des Vorlagendokuments des Auftragnehmers eines bestimmten Typs aus (falls vorhanden).
Zusätzliche Information:
- Damit der Textklassifizierungsdienst einen Typ auswählen kann, wählen Sie in mindestens einer Form für das Feld „Typ“ die Optionen „Empfehlung anzeigen“ und „Höchstwahrscheinliches Element einfügen“.
- Wenn der Klassifizierer den wahrscheinlichsten Typ angegeben hat, werden Empfehlungen nur für diesen Typ abgefragt (Beispiel: Wenn im Typ „Kaufrechnung“ (Formular „Kaufrechnung“) die Option „Wahrscheinlichsten Artikel einfügen“ für “ Die Felder Typ “und„ Kategorie “sowie der Klassifizierer gaben an, dass es sich um den Typ„ Verkaufsrechnung “(Formular„ Verkaufsrechnung “) handelt. Wenn diese Option nicht ausgewählt ist, werden die Felder nicht ausgefüllt.
- Ein Dokument ohne Typ und Kategorie wird nicht erstellt (die Meldungen „Unbekannter Dokumenttyp“ oder „Unbekannte Dokumentkategorie“).
- Mit den Optionen „Hot Folder“ und „Add Multiple with OCR“ wird ein neues Dokument erstellt und in der Datenbank gespeichert. OCR im neuen Dokumentformular füllt nur die Felder aus (es wird kein neues Dokument erstellt oder die Werte in der Datenbank gespeichert).
AI hot folder
AI Hot Folder ist das am weitesten fortgeschrittene Szenario des oben beschriebenen Prozesses. Aus Sicht des Benutzers platziert er Dokumentenscans an einer Stelle. Das System selbst unterteilt sie dann mithilfe von Textklassifizierungsdiensten in entsprechende Felder (Kategorien).
Im Folgenden finden Sie eine kurze Beschreibung der Funktionen des Systems nach dem Hinzufügen einer Datei zum AI hot folder:
- Führt einen OCR-Prozess (Image To Text) durch
- Es werden 3 Hauptmerkmale basierend auf der Klassifizierung bestimmt: Firma, Dokumenttyp, Kategorie. Basierend auf diesen Funktionen werden Dateien in geeigneten Kategorien angeordnet
- Startet den Prozess zum Erstellen eines Dokuments basierend auf der Datei
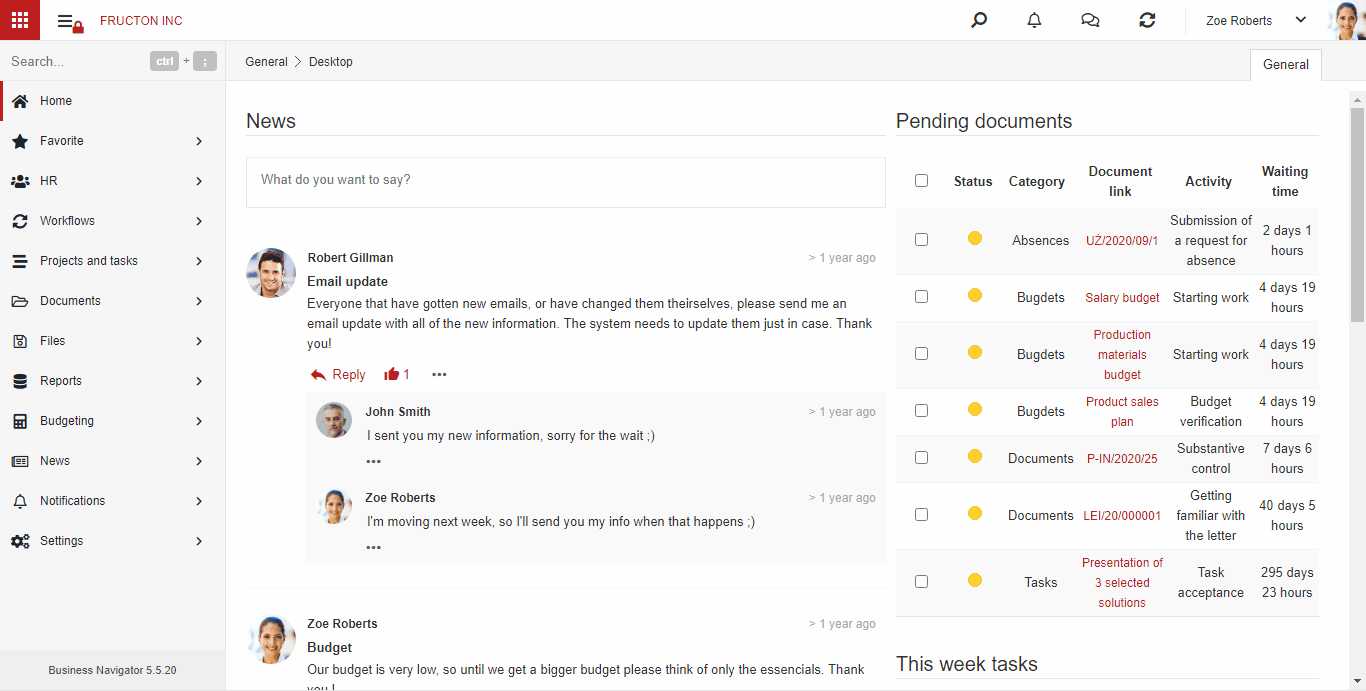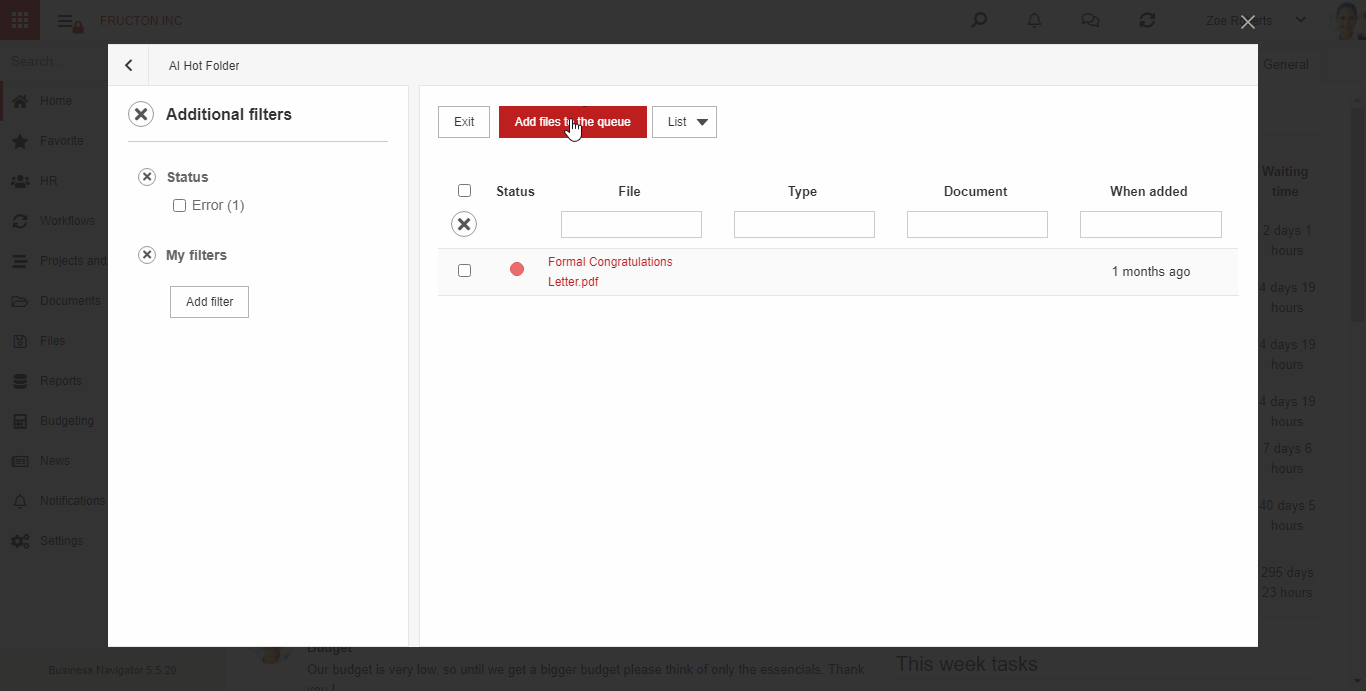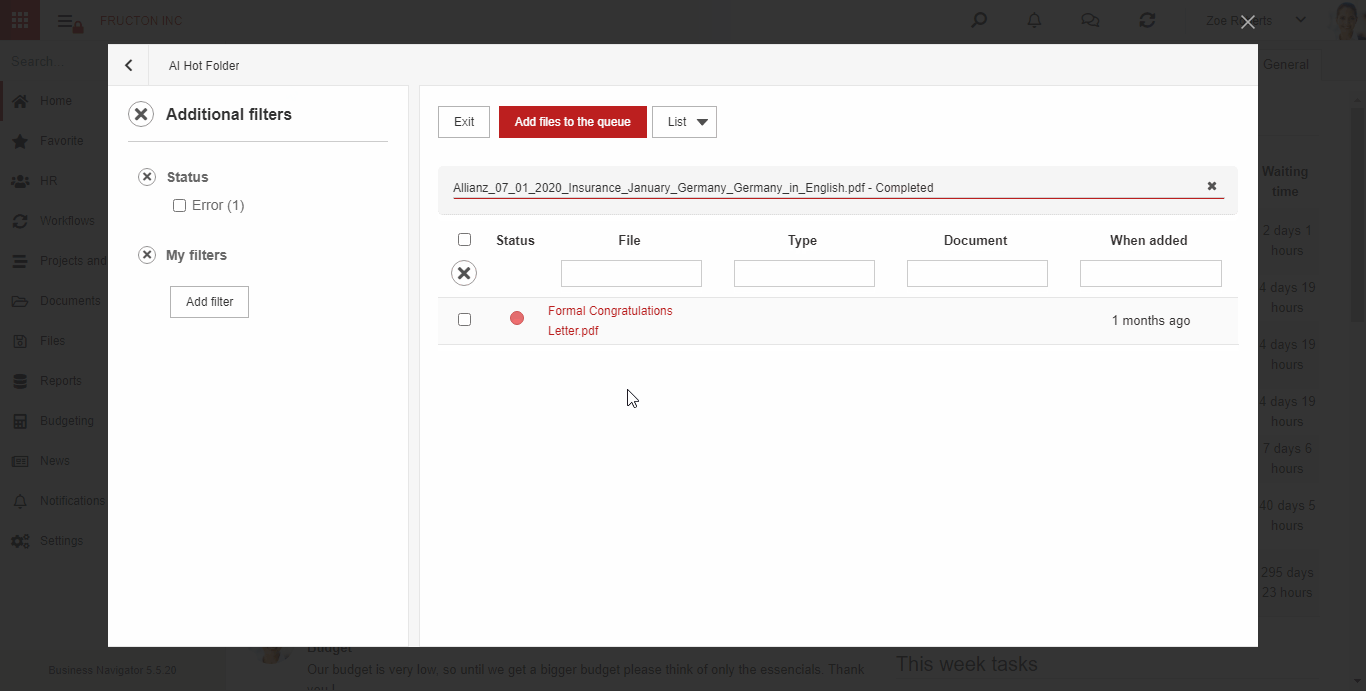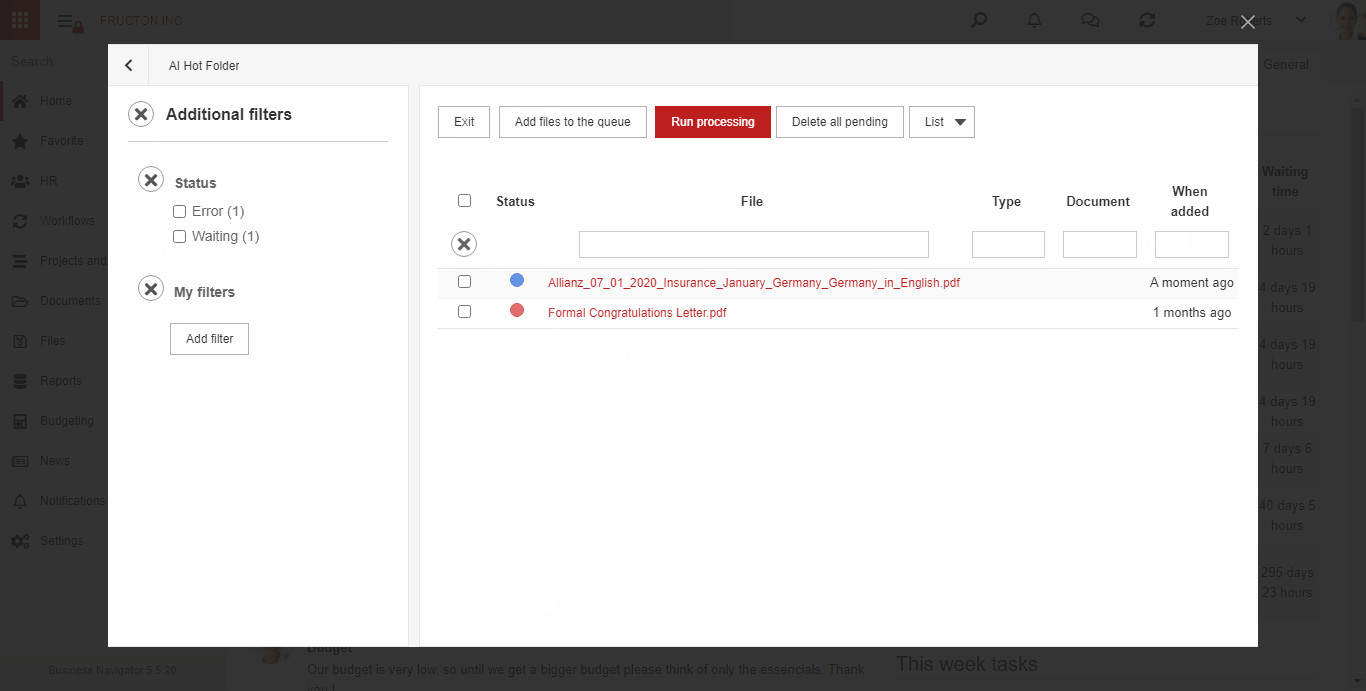
Die Schritte sind im obigen Abschnitt OCR BN ausführlich beschrieben.
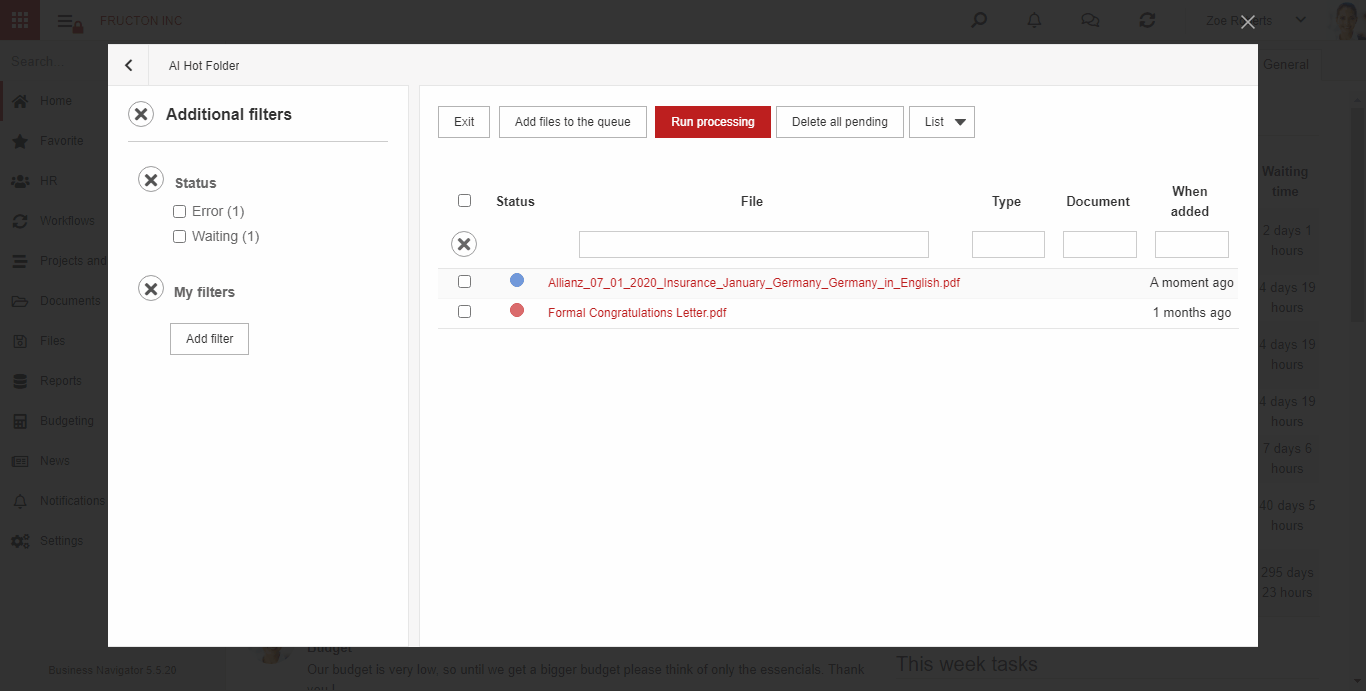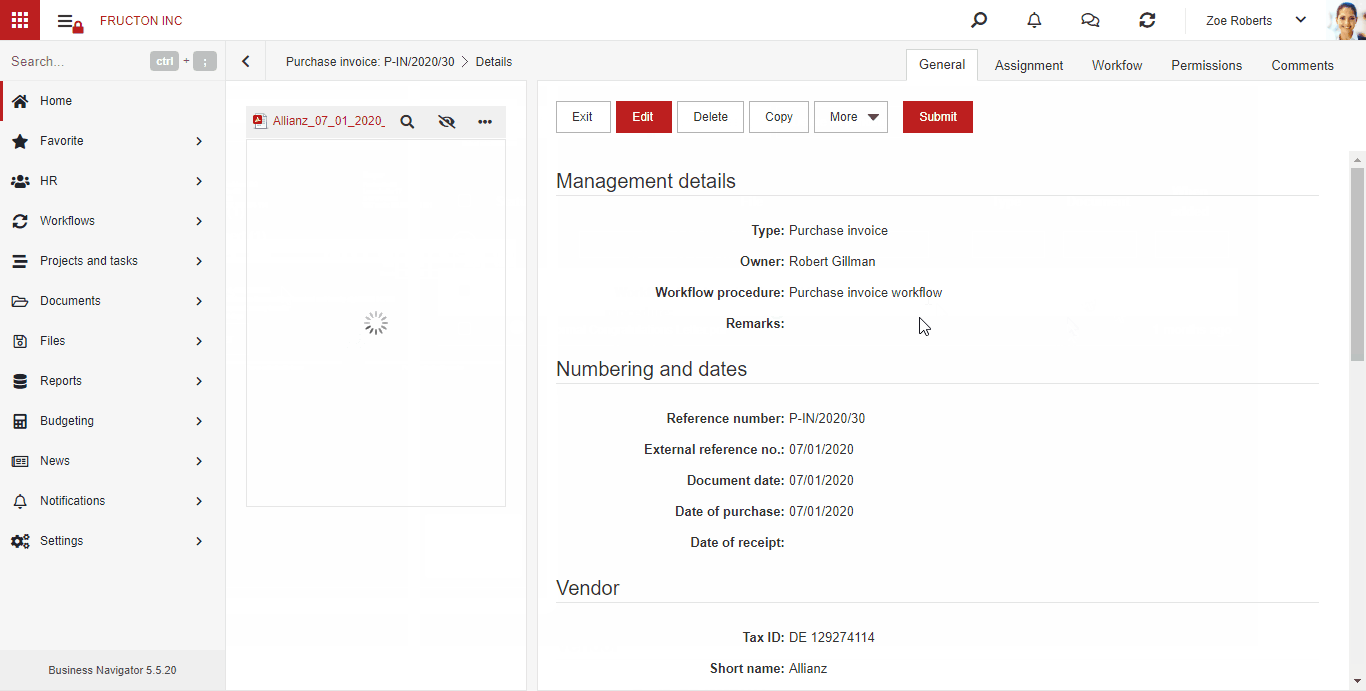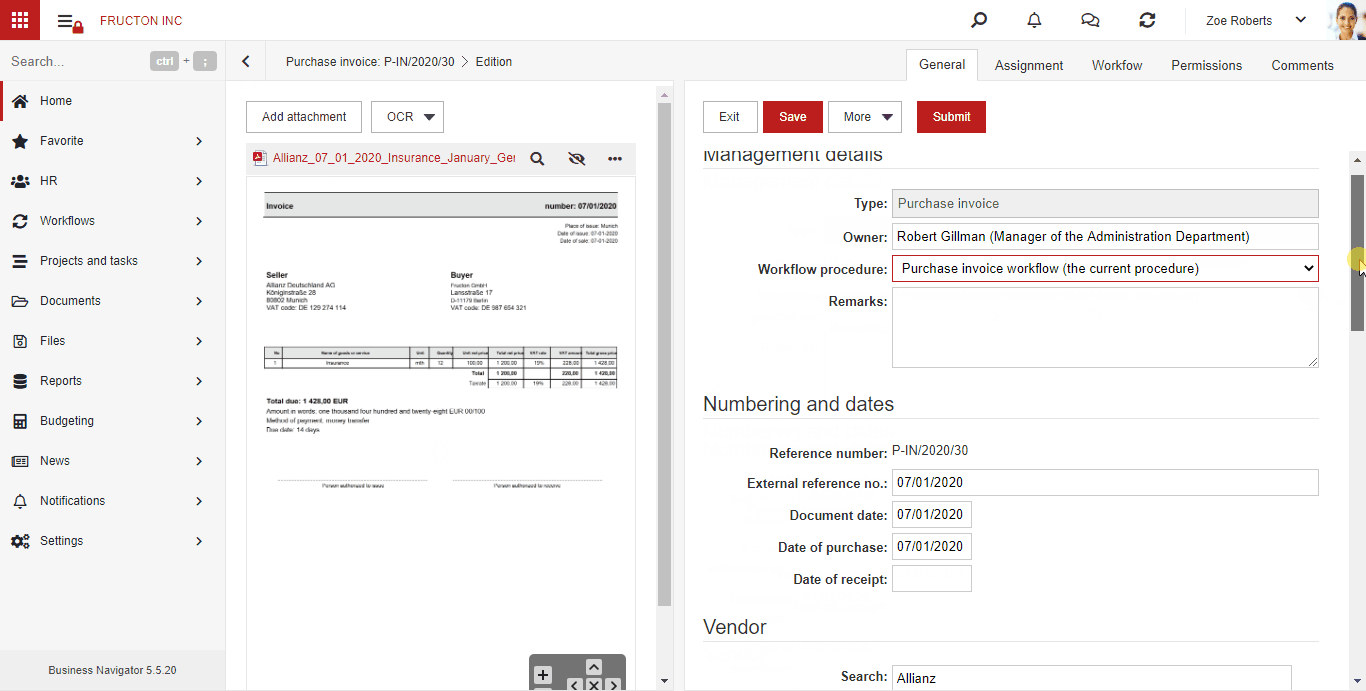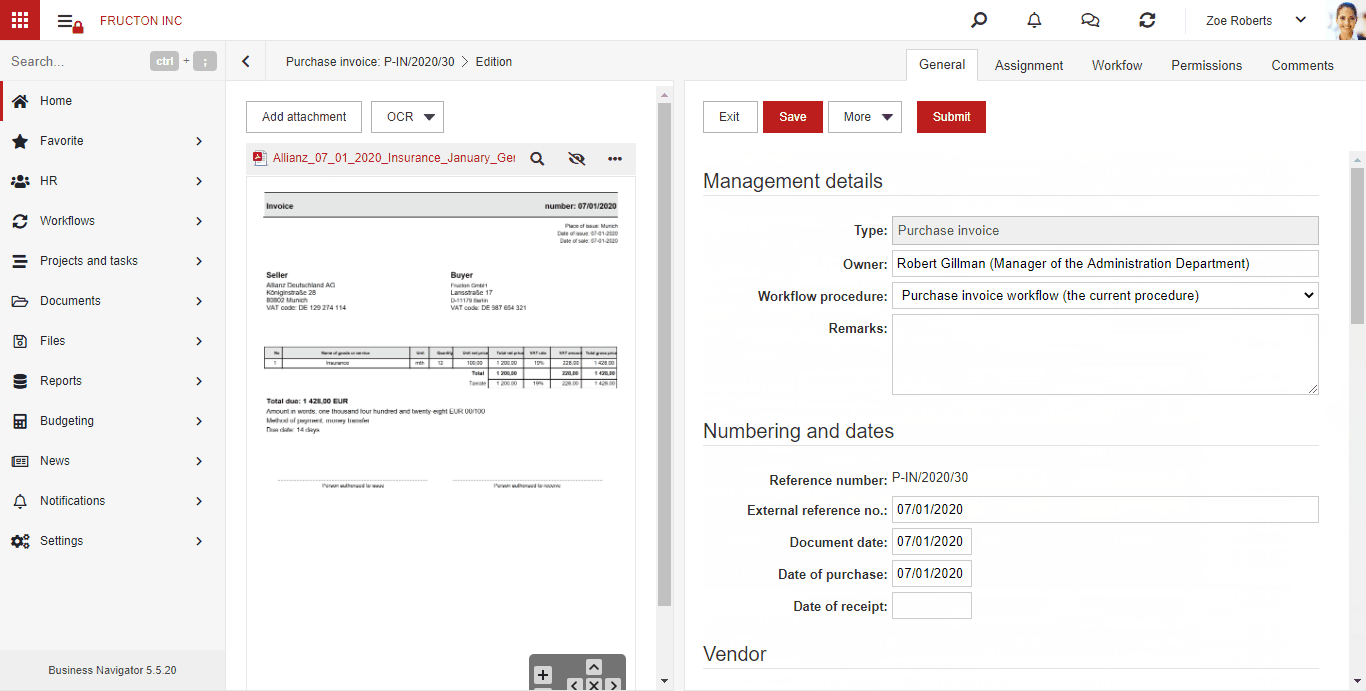
Im Moment arbeitet der Dienst innerhalb von Dokumenten.
Einrichten des Datenerfassungsdetailmodells
Mit dem detaillierten Datenerfassungsmodell können Sie jeden Wert aus jedem Dokumenttyp erfassen.
Um mit einem detaillierten Modell zu arbeiten, aktivieren Sie zunächst die Schaltfläche „Detailliertes Modell aktualisieren“, indem Sie es dem Dokumentmenü hinzufügen, das dem Prozess „OCRing“ unterliegt. Um die Schaltfläche zu aktivieren, gehen Sie zum Modul Einstellungen -> Personalisierung -> Menü, wählen Sie das Menü aus der Liste aus, die an das Dokument angehängt ist, und klicken Sie dann auf Bearbeiten. (Standardmäßig ist dies immer das Dokumentensystemmenü.) Wählen Sie nach dem Öffnen des Formulars in der linken Baumstruktur Mehr aus und klicken Sie dann auf Mehr -> Hinzufügen und konfigurieren Sie die Schaltfläche wie folgt im Formular, um eine neue Schaltfläche hinzuzufügen. Klicken Sie abschließend auf Speichern. Weitere Informationen zur Menükonfiguration finden Sie hier.
So trainieren Sie ein detailliertes Modell:
- Geben Sie min. 3 Dokumente (der Anhang muss „OCR-ed“ sein, d. H. Eine Textebene haben, die in das Formular eingegebenen Daten müssen korrekt sein)
- Klicken Sie für jedes Dokument auf „Detailliertes Modell aktualisieren“. Dieser Vorgang kann abhängig von der Anzahl der Felder im Formular und der Anzahl der Seiten im Dokument bis zu mehreren Minuten dauern.
Nach diesen beiden Schritten ist das Modell fertig. Um es zu testen, müssen Sie den OCR-Prozess für das nächste Dokument ausführen.
Während des OCR-Prozesses hat das System:
- Zunächst wird eine Datenerfassung basierend auf dem allgemeinen Modell (./data_capture/general/1/predict) durchgeführt.
- Anschließend führt es eine Datenerfassung basierend auf dem detaillierten Modell durch und füllt alle Felder aus, die erfasst werden können (./data_capture/templates///template_idarzenia/predict).
Die folgende Animation zeigt, wie benutzerdefinierte Informationen von einer Rechnung erfasst werden.
Detaillierte Informationen zum Training des detaillierten Modells
Das Training des detaillierten Modells erfolgt über den Dienst AI / data_capture / templates / {template_id} / fit
Formularfelder, die zur Schulung gesendet werden:
- Fremdnummer (Spalte [ForeignNumber] aus der Tabelle [Do])
- Dokumentdatum ([DocumentDate])
- Zahlungsdatum ([PayDate])
- Bankkontonummer des Auftragnehmers (Spalte [AccountNumber] mit [CoAc])
- Identifikationsnummer des Auftragnehmers (Spalte [NIP] mit [Co]) aus den Feldern „Auftragnehmer“ und „Auftragnehmer bearbeiten“
- Währung (Spalte [Symbol] aus Tabelle [Cu])
- Beschreibung ([Description])
- Nettobetrag ([Net])
- Mehrwertsteuerbetrag ([Nat])
- Bruttobetrag ([Gross])
- alle Attribute (Spalte [Text] von [FlVa]) vom Typ:
- Textfeld
- Mehrzeiliges Textfeld
- Datum
- Datum und Uhrzeit
- Ganzzahl
- Gleitkommazahl
Detaillierte Informationen zum Lesen von Informationen aus dem detaillierten Modell
Schritt 1:
Zunächst wird der Service für das Rechnungsmodell abgefragt ./data_capture/general/[model_idarzenia/predict. Es wird eine XML-Datei zurückgegeben, die folgendermaßen aussieht:
- Fremdnummer (Feldname in XML ABBYY: _InvoiceNumber)
- Dokumentdatum (_InvoiceDate)
- Zahlungsdatum (_DueDate)
- Ereignisdatum (_FactDate)
- Auftragnehmer (basierend auf NIP mit _VATID oder _VATID1 je nach Unternehmen)
- Bankkontonummer des Auftragnehmers (_BankAccount)
- Elemente (_LineItems):
- Maßeinheit (_UnitOfMeasurement)
- Mehrwertsteuersatz (_VATPercentage)
- Menge (_Quantity)
- Sortiment (_Description)
- Bruttowert (_TotalPriceBrutto)
- Nettobetrag (_TotalPriceNetto)
- Mehrwertsteuerwert (_VATValue)
- Mehrwertsteuersätze:
- Mehrwertsteuersatz (_TaxRate)
- Nettowert (_NetAmount)
- Mehrwertsteuerwert (_TaxAmount)
- Bruttowert (_GrossAmount)
Schritt 2:
Das System prüft dann, ob es für diesen Kunden und diesen Dokumenttyp ein detailliertes Modell gibt (./data_capture/templates/list). Wenn dies der Fall ist, wird der Dienst abgefragt ./data_capture/templates/[template_idarzenia/predict. Die zurückgegebenen Daten werden der in Schritt 1 erhaltenen XML-Datei nur hinzugefügt, wenn das allgemeine Modell sie nicht abgeschlossen hat. Zusätzlich werden Zweige hinzugefügt:
- Beschreibung (_Description)
- Währung (_Currency)
- Attribute (_Attributes)
Diese vorbereitete Datei wird in der Tabelle „Fi“ in der Spalte „OcrData“ gespeichert. Diese Datei wird verwendet, um Daten im Dokumentformular zu vervollständigen.