



Introduction
In Navigator, AI solutions operate in two layers:
- Service layer – API methods that can be called for specific implementation tasks
- Implementation layer in the Navigator system – specific system functionalities using AI services in specific areas
Machine learning has been implemented for Windows 10 and Linux.
AI services
AI services are made available in the container architecture. A specific set of services that can cooperate with each other are closed within the so-called docker – a portable virtual container that can be run on a Linux server. Docker installation is quick and easy. The services operate in the customer’s infrastructure and do not require data sharing outside (to the cloud).
OCR
The purpose of OCR (optical character recognition) is to generate text or a searchable PDFA from an uploaded photo or PDF file.
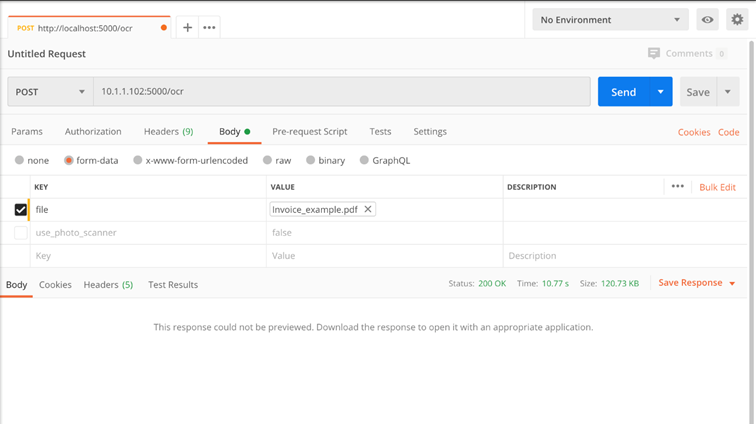
Method: ./ocr
Input parameters:
- file – file jpg/jpeg, png, tif, pdf
- use_photo_scanner – true by default. When loading a photo of a document taken with a smartphone, the system applies a set of filters (increasing contrast, removing shadows, etc.), which increase the effectiveness of OCR
Returns:
· file – PDFA file (searchable PDF)
Example:
Text classification
The purpose of this group of services is to determine any class (document type, category, owner, account number etc.) based on the analysis of the text on the document.
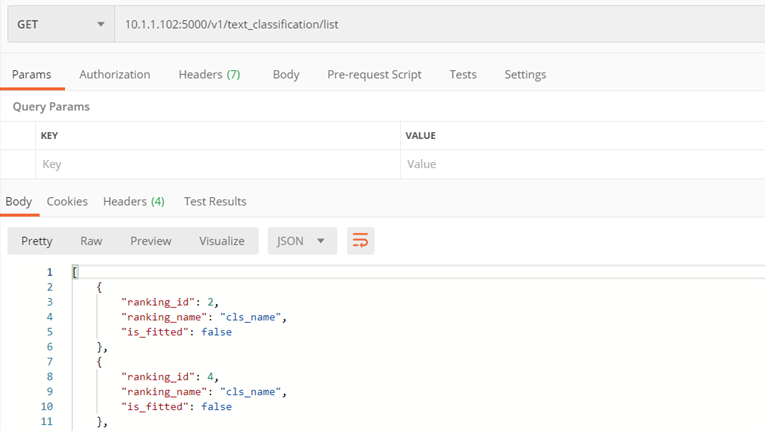
Method ./v1/text_classification/list
The purpose of the method is to return a list of classifiers saved on the server
Input parameters:
- none
Returns:
- List of available classifiers, including
- ranking_id – classifier id,
- ranking_name – classifier name,
- is_fitted – whether is learnt
Example:
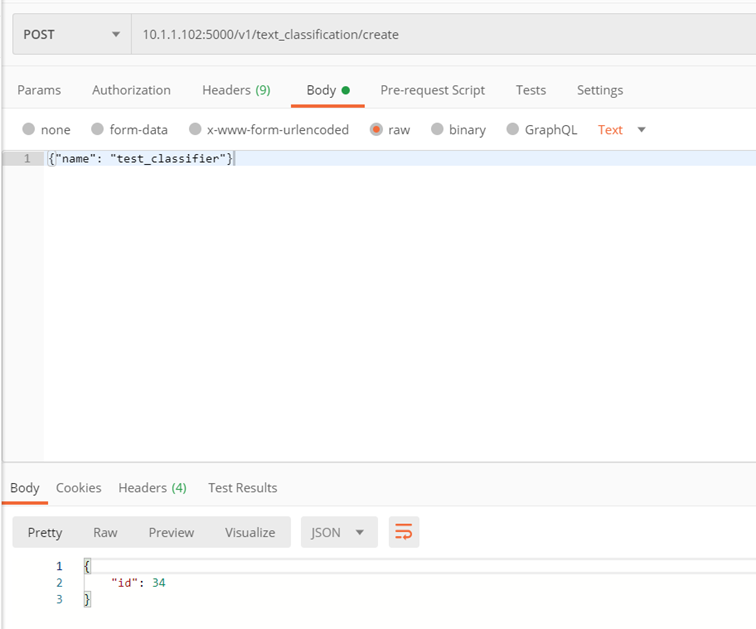
Method: ./v1/text_classification/create
The purpose of the method is to create a classifier.
Input parameters:
- name – classifier name
Returns:
- classifer_id – id of the created classifier
Example:
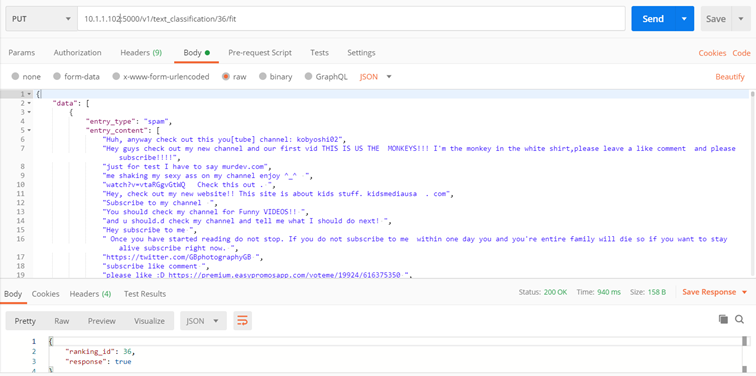
Method: ./v1/text_classification/{classifier_id}/fit
The purpose of the method is to train the classifier
Input parameters:
- classifier_id – classifier id
- collection (collection of learning texts)
- entry_type – class name (e.g. invoice, CV, letter etc.)
- entry_content – text block (complete document content, anything OCR returns)
Returns:
- code 200 – positive learning of the model
- code 422 – error (an error message is returned)
Example:
Method: ./v1/text_classification/{classifier_id}/remove
The purpose of the method is to remove the classifier
Input parameters:
- classifier_id – id of the classifier that we want to remove from the server
Returns:
- code 200 – positive model deletion
- code 422 – error (an error message is returned)
Example:
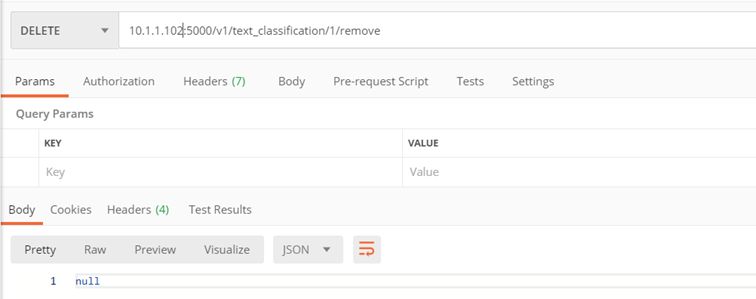
Method: ./v1/text_classification/{classifier_id}/predict
The purpose of the method is to perform text classification for a given classifier
Input parameters:
- classifier_id– id of the classifier on the basis of which the classification is to be performed
- text – the text to be classified
- file – the PDFA file to be classified
Comments :
either file or text can be given.
Returns:
- Probability-ranked collection of classes for the passed text:
- pred_proba – probability
- type_id – class
- rank – position in the ranking
Example:
Data capture
The purpose of this group of services is to capture data from the examined document. For example, for invoices, these are: invoice number, tax identification numbers, dates, account number, rates and VAT amounts, table with document items
Method ./v1/data_capture/general/list
Returns the currently available generic models
Input parameters:
- none
Returns:
- List of available generic models with their id
Example:
Method ./v1/data_capture/general/{model_id}/locale/list
The purpose of the method is to return the supported languages and the prefixes available in them
Method only for the general model of invoices – no. 1
Input parameters:
- model_id – id of the model whose prefixes will be returned by the method
Returns:
- List of dictionaries with information about the supported languages and the prefixes available in them
Example:
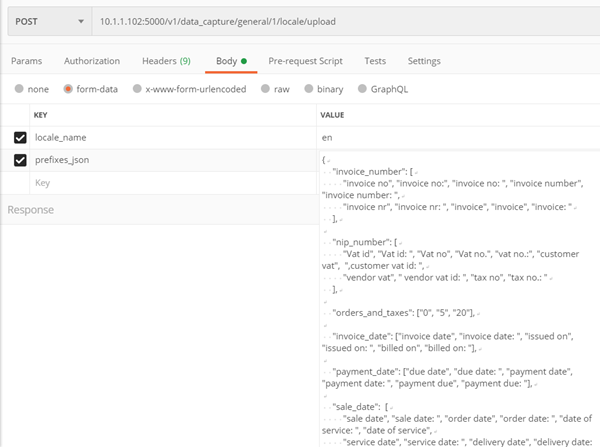
Method ./v1/data_capture/general/1/locale/upload
It allows you to add your own supported language by entering prefixes
Method only for the general model of invoices – no. 1
Parametry:
- locale_name – the name of the local (language), the prefixes of which we want to pass, must be one of:
af, ar, bg, bn, ca, cs, cy, da, de, el, en, es, et, fa, fi, fr, gu, he, hi, hr, hu, id, it, ja, kn, ko, lt, lv, mk, ml, mr, ne, nl, no, pa, pl, pt, ro, ru, sk, sl, so, sq, sv, sw, ta, te, th, tl, tr, uk, ur, vi, zh-cn, zh-tw
- prefixes_json – a dictionary containing for each of the keys (invoice_number, nip_number, orders_and_taxes (vat_rates), invoice_date, payment_date, sale_date) a list of prefixes in a given language
Returns:
- Code 200 – positive learning of the model
- Code 400 – error
Example:
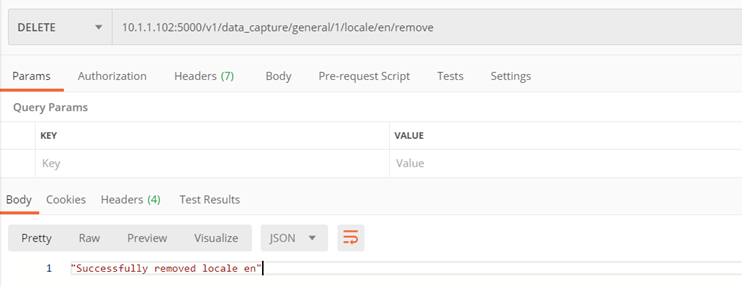
Method ./v1/data_capture/general/{model_id}/locale/{locale_name}/remove
Supported language removal
Method only for the general model of invoices – no. 1
Input parameters:
- locale_name – name of the language to be removed, e.g. ‘en’
- model_id – model id from which we remove locale
Returns:
- Code 200 – successful removal
Example:
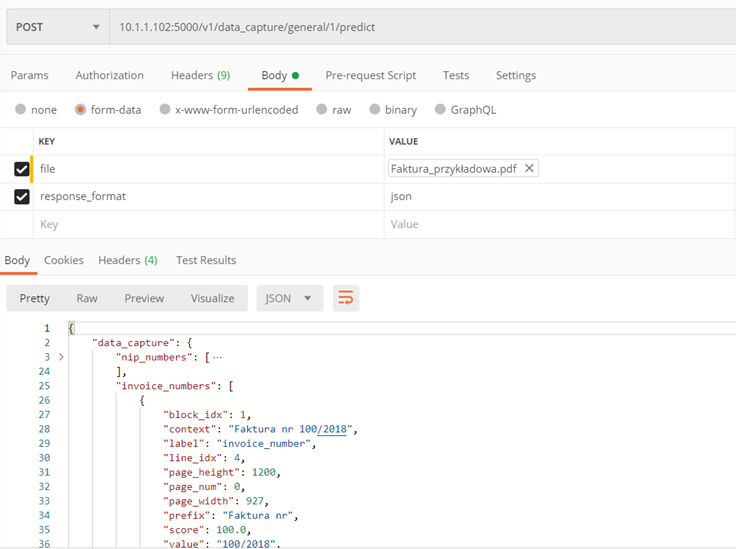
Method ./v1/data_capture/general/{model_id}/predict
Return information contained in the text of the uploaded file.
Input parameters:
- model_id – model id with which we will perform the prediction
- file – searchable PDF file
- locale (optional) – document language name. If not specified, the program will determine the language from the text itself and use the corresponding prefixes
- response_format (optional) – the format in which the information will be returned, to choose from: none, xml, json
Returns:
- Information obtained from the text in json or xml format
Example:
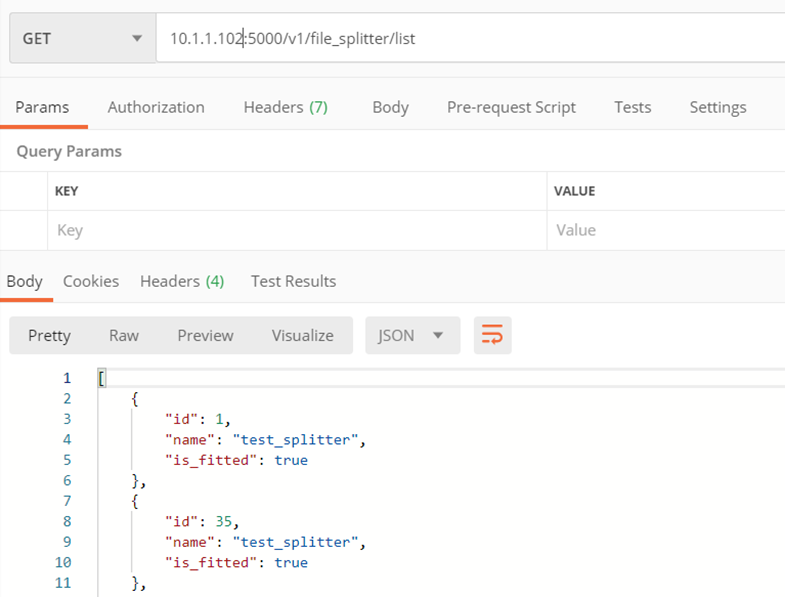
File splitter
A service that separates documents scanned together into one file into separate files, with each file representing a separate document. It has the ability to teach any number of own splitters for your own type of documents
Method ./v1/file_splitter/list
Returns a list of splitters (models)
Input parameters:
- none
Returns:
- A list of available splitters, containing for each: its name, id and information whether it is learned
Example:
Method ./v1/file_splitter/create
Create your own splitter
Input parameters:
- name – splitter name
Returns:
- Created splitter id
Example:
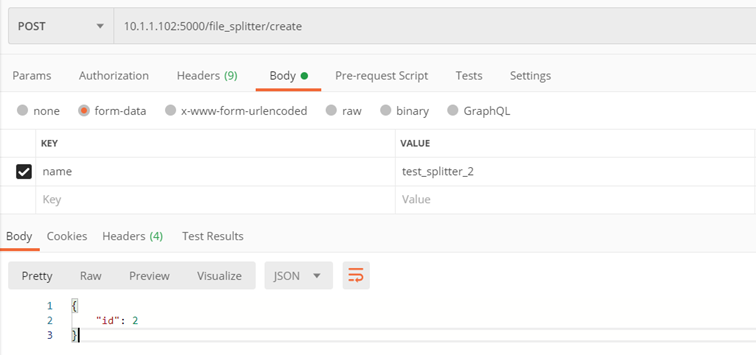
Method ./v1/file_splitter/{splitter_id}/fit
Teaching a document splitter
Input parameters:
- splitter_id – id of the splitter we want to learn
- files – a list of files on the basis of which splitter will learn to split documents
Returns:
- Code 200 – correctly learned splitter
- Code 400 – error
Example:
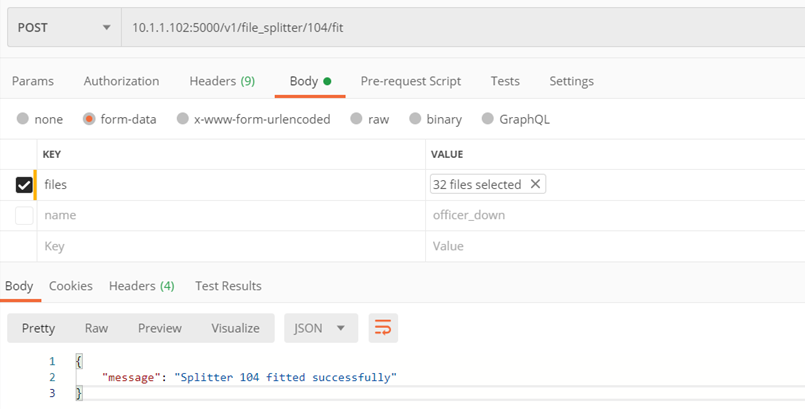
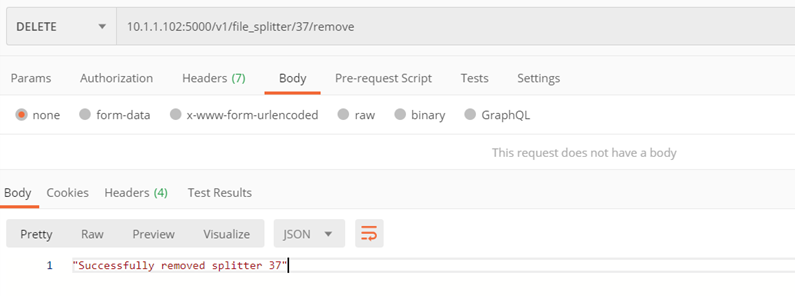
Method ./v1/file_splitter/{splitter_id}/remove
Removal of the selected splitter
Input parameters:
- splitter_id – id of the splitter to be removed
Returns:
- Code 200 – positive removal
- Code 400 – error
Example:
Method ./v1/file_splitter/{splitter_id}/split
Split a file with multiple documents into single ones
Input parameters:
- splitter_id – id of the splitter that we use for splitting the file
- file – the searchable PDF file we want to split
Returns:
- Zip file with separate pdf files saved
Example:
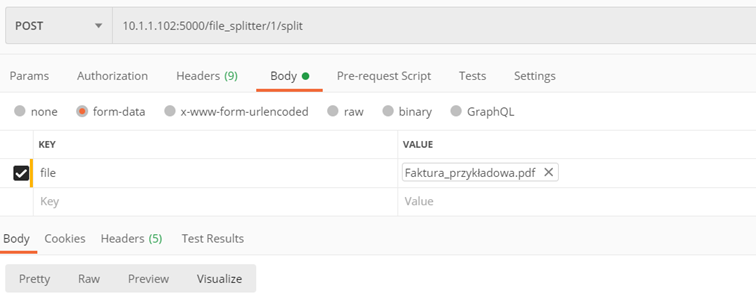
Implementation of AI services in Navigator
To start working with the AI service, you need to make some changes, which will include the database and the Navigator. First, you need to enter the settings in the base, and then you can go to the settings in the system.
Database settings
Enable the AI service
In order for AI services to be active, the correct AI server address must be entered in the system database in the [Sg] settings table. Checking which address is currently set is done by entering the command: SELECT * FROM Sg WHERE Code = ‘Address_AI_API’ and executing it.
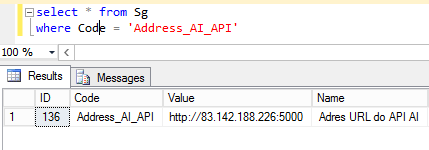
Due to update the value displayed in the Value column, enter the command:
UPDATE Sg SET Value = ‘Value of the new address’ WHERE Code = ‘Address_AI_API’ and execute it.
Determining the training set
The training set is the set of documents on the basis of which the service is learned. From the database level, you can define how many documents are to be in the training set. To check the quantity, enter the command: SELECT * FROM Sg WHERE Code = ‘MaxFilesPerType’. By default, this value is 50.

Due to update the value displayed in the Value column, enter the command:
UPDATE Sg SET Value = ‘Ilość dokumentów’ WHERE Code = ‘MaxFilesPerType’ and execute it.
Automatic model refresh
All models are set to auto-refresh every day when you first log into the system. To disable / enable automatic refresh, change the value in the table [Sg]. Checking if the automatic refresh is turned on is done by entering the command: SELECT * FROM Sg WHERE Code = ‘RecommedationAutoRefreshModel’

The Value column contains the value that is responsible for the automatic refresh.
- 0 – disabled
- 1 – enabled
To update the value displayed in the Value column, enter the command:
UPDATE Sg SET Value = ’0 lub 1’ WHERE Code = ‘RecommedationAutoRefreshModel’ and execute it.
System settings
Recommendations on the form fields
The AI Text classification service is used to recommend values in selected fields of the form. The learned model is run in the attachment OCR process. After completing the OCR work, the effect in this field will be as follows:
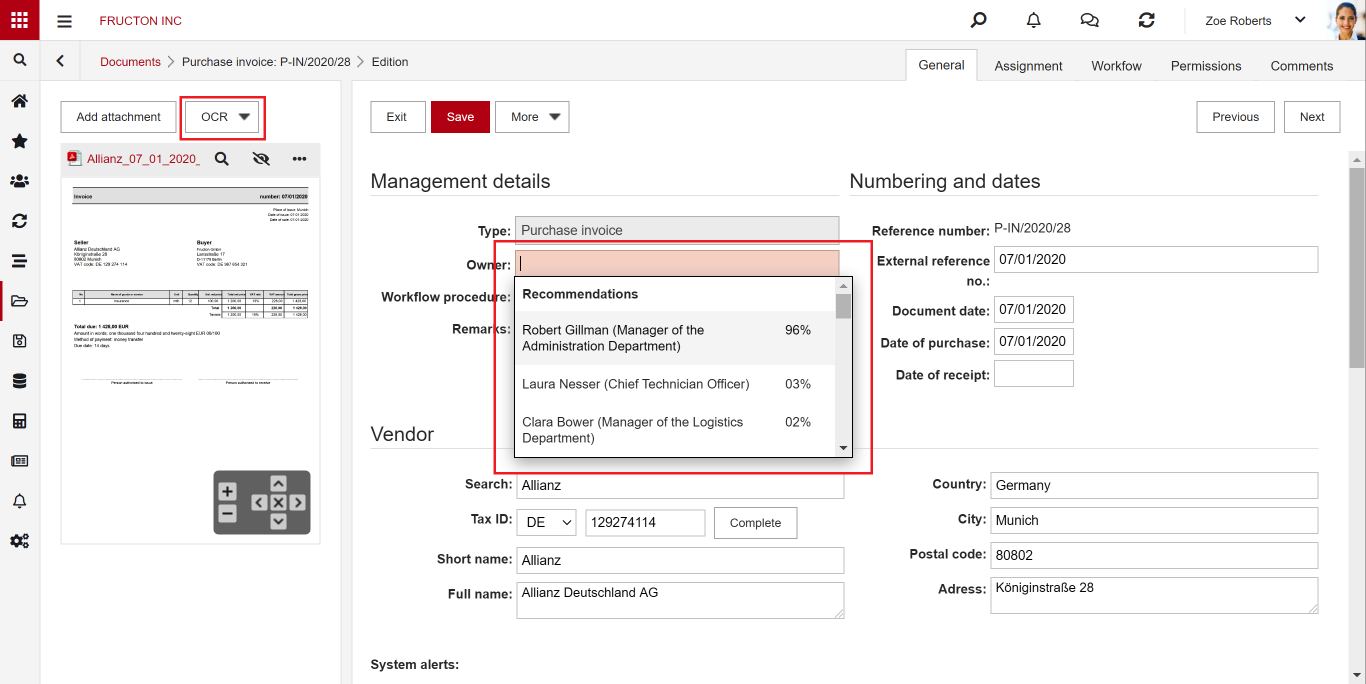
Create the model
To create a model for a specific field, select Show recommendations.
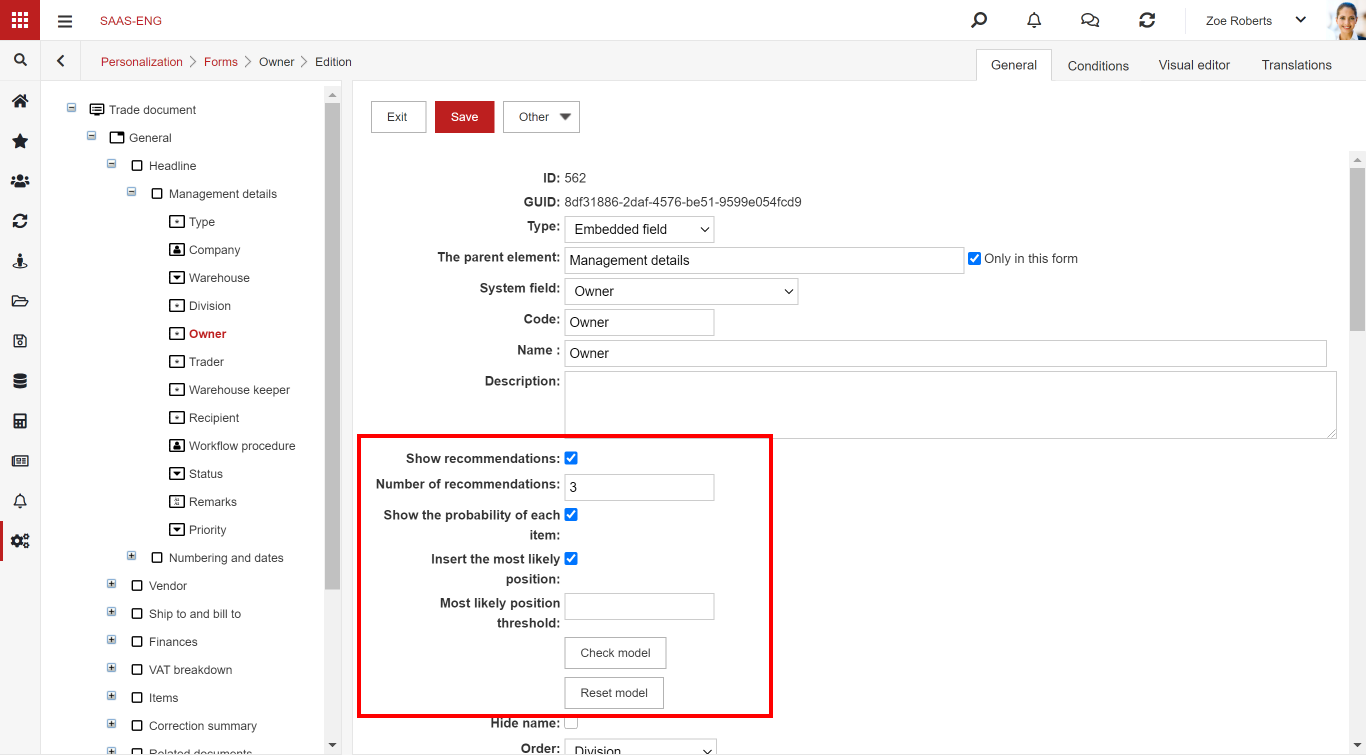
At the moment, the option is available for the system fields: contractor, contractor – edit, owner, company, category, type and auto search type attribute.
After clicking “Save”, the model is trained (in the background). It takes approx. 20 seconds. After this time, after the OCR process is completed, recommendations in this field should appear on the document. If they do not appear, wait a long time (about 10 minutes). Perhaps the training process is longer (e.g. due to a larger training set or the server load).
Important:
- The model will work if there are a sufficient number of correctly entered documents in the database. It’s best to provide more than 20 examples for each class (e.g. 20 documents with completed owner)
- Ideally, the distribution in each class should be balanced (e.g. invoices assigned to different owners)
- The Business Navigator system downloads only the latest data for the learning process. Only documents with attachments that are OCRed (have data in [OcrText] in table [Fi]) are taken into account.
- The model is saved on the AI services server with the name CodeCompany_FieldType_FieldID (e.g. FRUCTON_FlSy_5, FRUCTON_FL_8660), where:
- CompanyCode – CompanyCode from the table [Sg]
- FieldType – FlSy for system fields, Fl for attributes or Di for dictionaries
- FieldID – ID from the FlSy, Fl, or Di table
- It is not possible to delete a model from the AI server from Business Navigator. To stop using it, just uncheck the Show recommendations box. To remove the model from the AI server, use the API.
- Due to update the model, click “Reset model” (the model is deleted and the learning process starts again).
OCR BN
Under the name of the OCR engine “BN” is a set of AI services: OCR, Text Classification, Data capture. Additionally, the system performs other automation processes (e.g. loading a model document, downloading contractor’s data from the Central Statistical Office, etc.)
We choose the engine for a specific type of document.
Steps in the OCR process performed by the BN engine:
- OCR
- If the attachment does not contain text (not a searchable PDF or not previously OCRed) it is sent to API AI (/ ocr)
- the returned searchable PDFA is saved in the Navigator database in the “Fi” table in the “PdfFile” column)
- Data capture
- The PDFA file is sent to the API AI process (./data_capture/general/1/predict). The API returns the xml file and the plain text of the file.
- Plain text is saved in the Navigator database in the “Fi” table in the “OcrText” column
- The XML file is saved in the Navigator database in the “Fi” table in the “OcrData” column
- Text classification
- Plain text is sent to the “Text classification” API AI process (/ text_classification / {classifier_id} / predict). The process is performed for all models defined in all forms of the Documents area
- Decision which Company, Type of document, Category:
- When invoking OCR via “Add Multiple from OCR”, the engine uses the category and type known from the context of the call. Even if Text Classification has returned a different recommendation for these fields, it is not taken into account
- Similarly, for the selected company, it will also be set for the document regardless of the Text Classification indication
- If the “AI hot folder” is used, the system will determine the Type, Category, Company based on the highest recommended Text Classification indication. Warning! Each of these fields must be marked on at least one form with “Insert most likely position”.
- Contractor setting
- Data capture returns 2 NIPs (VATID and VATID1 fields). The contractor will be the one who is not “our company”, ie not assigned to any of the companies (Settings -> Files -> Companies -> Edit -> Contractor).
- If there is a contractor with this tax identification number in the Contractors file, it is inserted into the form
- If there is no contractor with this NIP number in the contractor file, it is loaded from the Central Statistical Office database
- Complete unfinished selection fields based on the Text classification recommendation
- Completing the blank fields based on the Data capture file (“OcrData” column in the “Fi” table)
- If the contractor for the selected document type has the Data capture detailed model, the AI service is started ./data_capture/templates///template_idarzenia/predict. The fields that have not been completed so far are completed with the values returned by this service.
- Complete the rest of the blank fields on the basis of the contractor’s template document of a given type (if any)
Additional information:
- In order for the Text classification service to select a Type, in at least one form for the “Type” field, select the “Show recommendation” and “Insert most likely item” options.
- If the classifier has indicated the most probable type, recommendations are prompted only for this type (example: If on the “Purchase invoice” type (“Purchase invoice” form) I have the “Insert most likely item” option selected for the “Type” and “Category” fields and the classifier indicated that it is the “Sales invoice” type (“Sales invoice” form), where this option is not selected, the fields will not be completed.
- A document without a type and category will not be created (the messages “Unknown document type.” Or “Unknown document category.”).
- The “Hot folder” and “Add multiple with OCR” options create a new document and save it in the database. OCR on the new document form only completes the fields (it does not create a new document or save the values to the database).
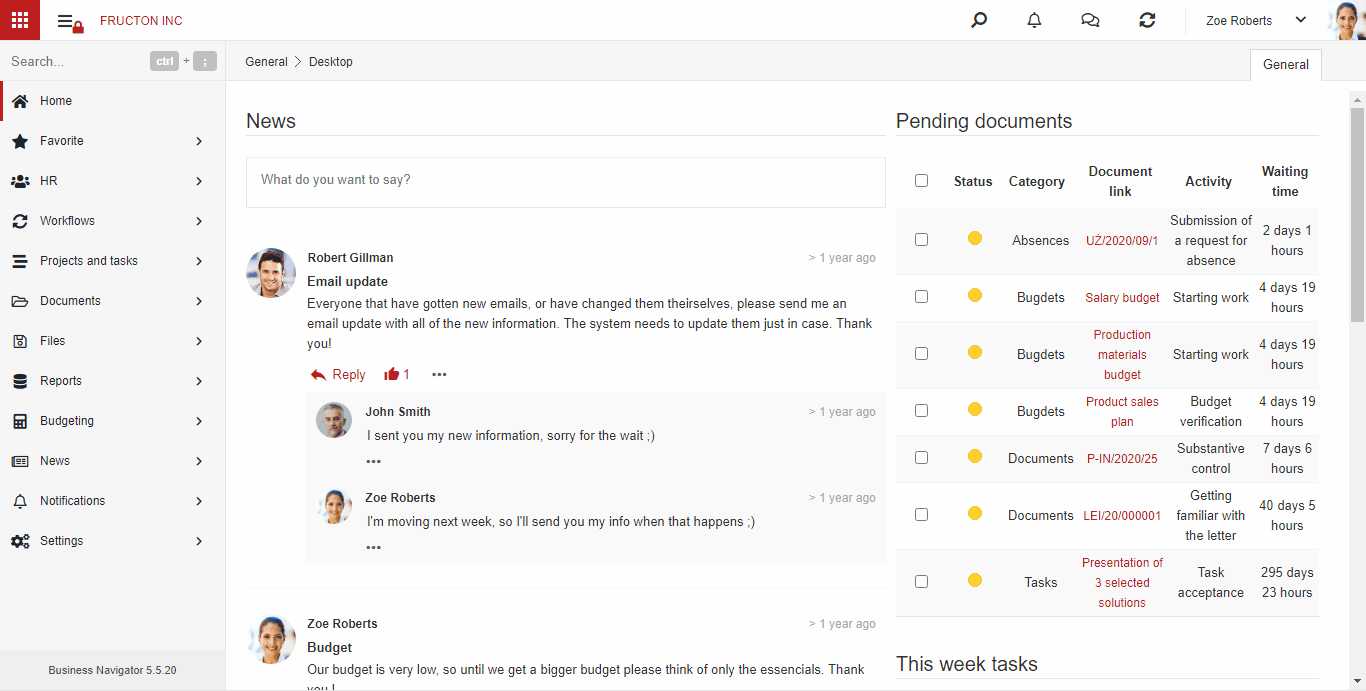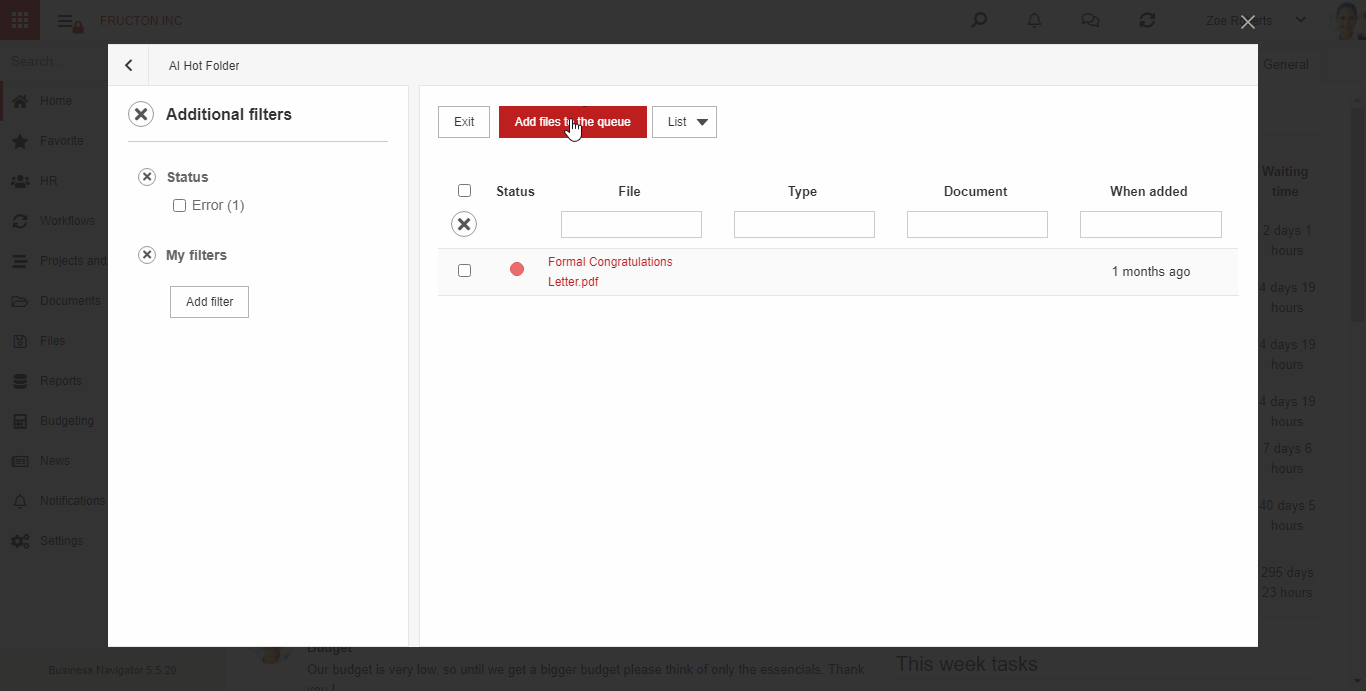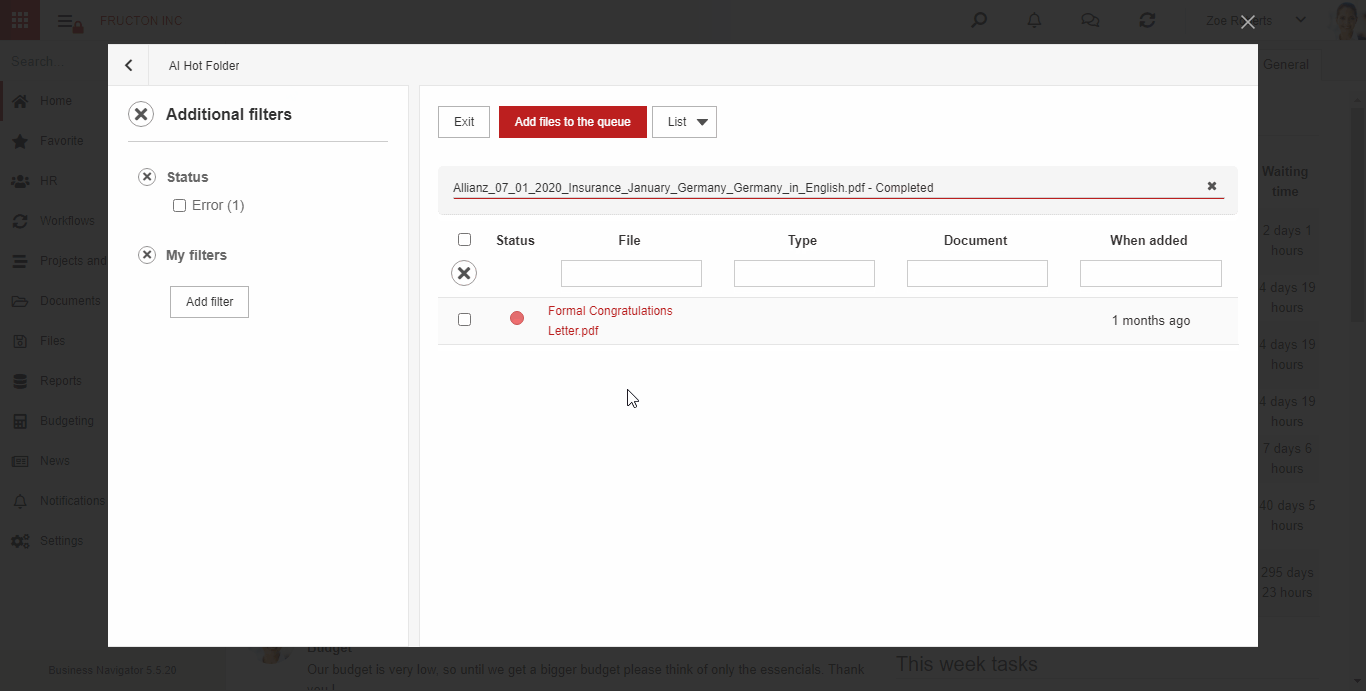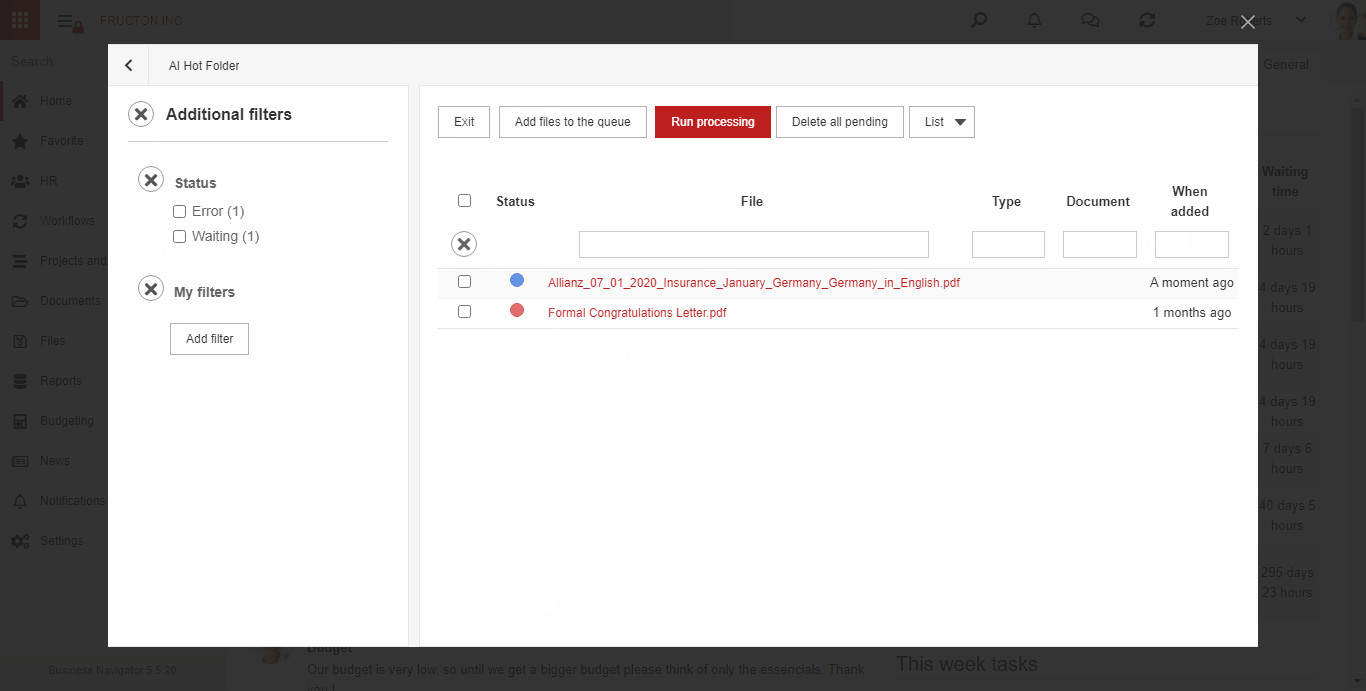
AI hot folder
AI hot folder is the most advanced scenario of the process described above. From the user’s point of view, he places document scans in one place. Then, the system itself divides them into appropriate boxes (categories) using text classification services.
Below is brief description what the system does after adding a file to the AI hot folder:
- Performs an OCR (Image To Text) process
- It determines 3 key features based on the classification: Company, Document type, Category. Based on these features, it arranges files into appropriate categories
- Starts the process of creating a document based on the file
The steps are described in detail in the OCR BN section above.
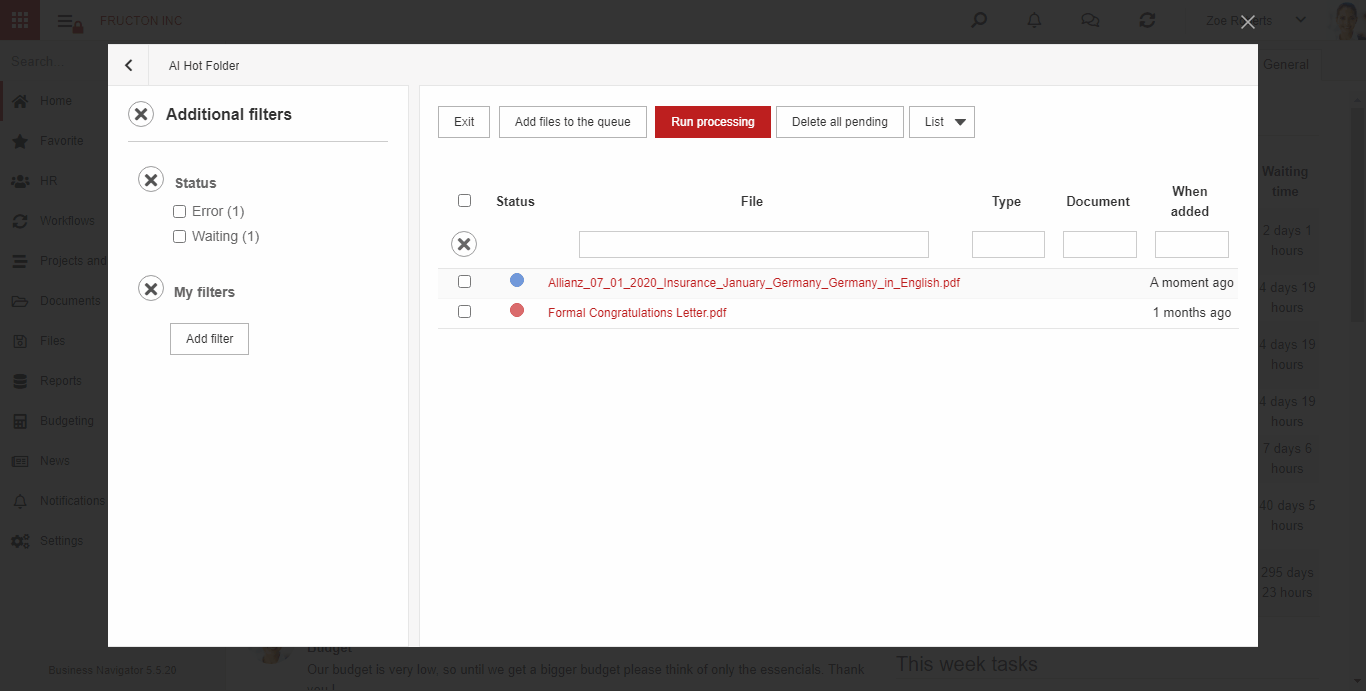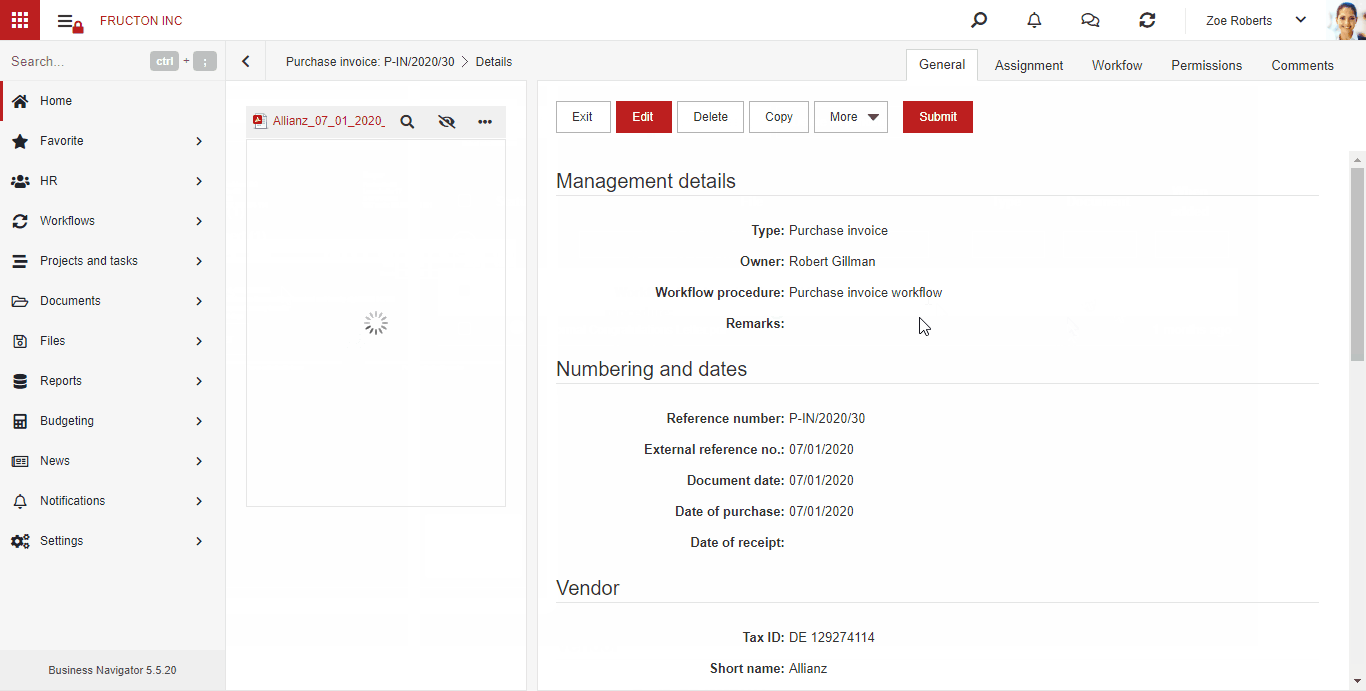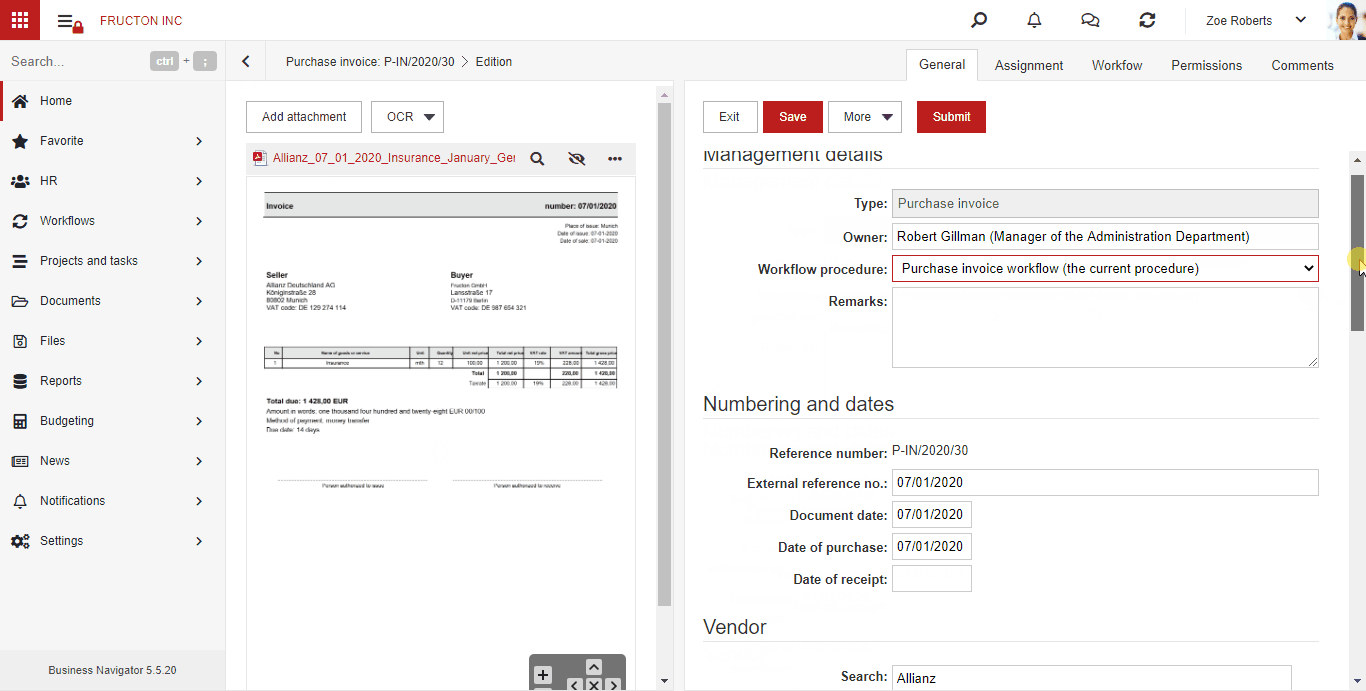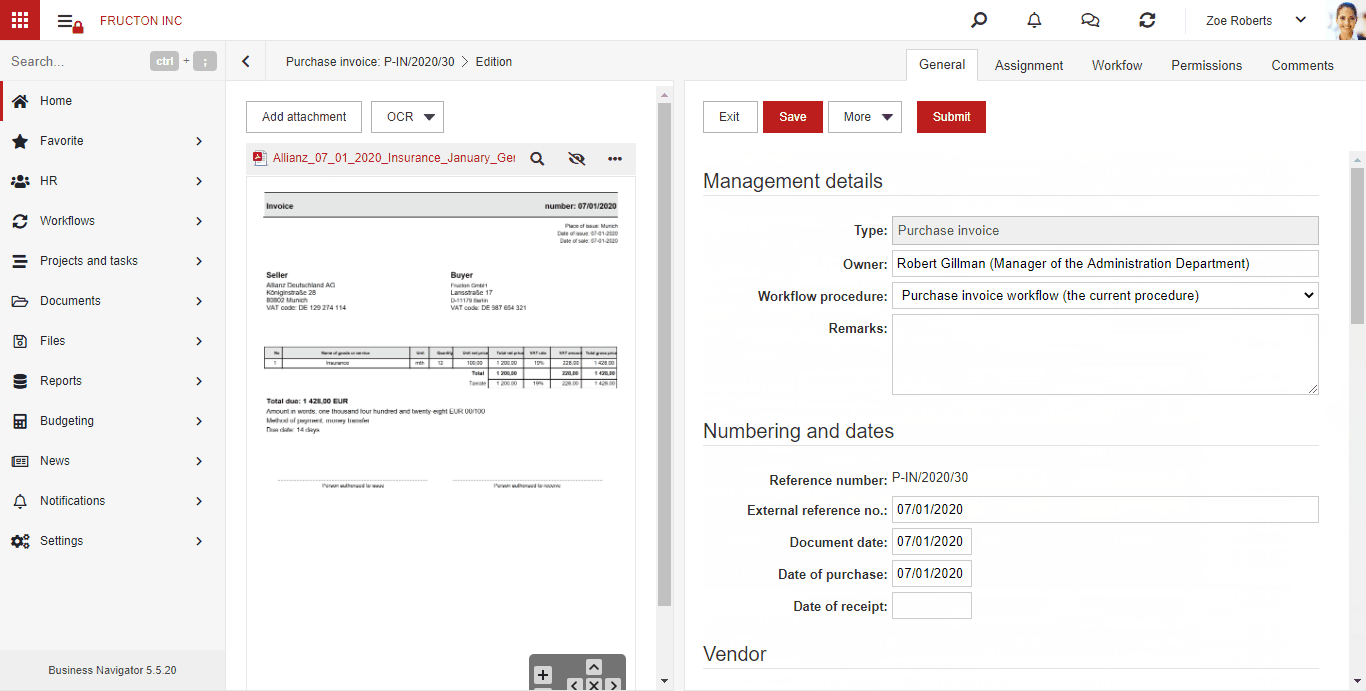
For now, the service works within documents.
Setting up the Data capture detail model
The data capture detailed model allows you to capture any value from any type of document.
To start working with a detailed model, first activate the “Update detailed model” button by adding it to the document menu, which will be subject to the “OCRing” process. To enable the button, go to the Settings -> Personalization -> Menu module, select the menu from the list that is attached to the document, and then click Edit. (By default, this is always the Documents System Menu.) After opening the form, select More from the tree on the left, then click More -> Add and configure the button as below in the form for adding a new button. Finally, click Save. You can learn more about the menu configuration here.
To train a detailed model:
- Enter correctly min. 3 documents (the attachment must be “OCR-ed”, i.e. have a text layer, the data entered into the form must be correct)
- For each of the documents, click “Update detailed model”. This process may take up to several minutes depending on the number of fields on the form and the number of pages in the document.
After these two steps, the model is ready. To test it, you must perform the OCR process for the next document.
During the OCR process, the system:
- First, it will perform data capture based on the general model (./data_capture/general/1/predict)
- Then it will perform data capture based on the detailed model and fill in any fields it manages to capture (./data_capture/templates///template_idarzenia/predict)
The animation below shows how to capture custom information from an invoice.
Detailed information on training the detailed model
Training of the detailed model is carried out via the AI / data_capture / templates / {template_id} / fit service
Pola formularza, które są wysyłane do uczenia:
- foreign number (column [ForeignNumber] from the table [Do])
- document date ([DocumentDate])
- payment date ([PayDate])
- contractor’s bank account number (column [AccountNumber] with [CoAc])
- contractor’s identification number (column [NIP] with [Co]) both from the “Contractor” and “Contractor edit” fields
- currency (column [Symbol] from table [Cu])
- description ([Description])
- net amount ([Net])
- VAT amount ([Nat])
- gross amount ([Gross])
- all the attributes (column [Text] from [FlVa]) of type:
- Text field
- Multirow text field
- Date
- Date and time
- Integer
- Float
Detailed information on how to read information from the detailed model
Step 1:
First, the service is queried ./data_capture/general/[model_idarzenia/predict for the invoice model. It returns an XML file that looks like this:
- foreign number (field name in XML ABBYY: _InvoiceNumber)
- document date (_InvoiceDate)
- payment date (_DueDate)
- event date (_FactDate)
- contractor (based on NIP with _VATID or _VATID1 depending on the company)
- contractor’s bank account number (_BankAccount)
- items (_LineItems):
- unit of measure (_UnitOfMeasurement)
- VAT rate (_VATPercentage)
- quantity (_Quantity)
- assortment (_Description)
- gross value (_TotalPriceBrutto)
- net worth (_TotalPriceNetto)
- VAT value (_VATValue)
- VAT rates:
- VAT rate (_TaxRate)
- net worth (_NetAmount)
- vat value (_TaxAmount)
- gross value (_GrossAmount)
Step 2:
The system then checks if there is a detailed model for this customer and this type of document (./data_capture/templates/list). If it is, the service is queried ./data_capture/templates/[template_idarzenia/predict. The data returned is added to the XML file obtained in step 1 only if the general model has not completed it. Additionally, branches are added:
- description (_Description)
- currency (_Currency)
- attributes (_Attributes)
Such prepared file is saved in the “Fi” table in the “OcrData” column. This file is used to complete data in the document form.