Usługi AI
Usługi AI udostępniane są w architekturze konteneryzacyjnej. Określony zestaw usług, które mogą ze sobą współpracować zamykane są w obrębie tzw. dockera – przenośnego wirtualnego kontenera, który można uruchomić na serwerze Linux. Instalacja dockera jest szybka i prosta. Usługi działają w infrastrukturze klienta i nie wymagają udostępniania danych na zewnątrz (do chmury).
OCR
Celem OCR (optical character recognition) jest wygenerowanie tekstu lub PDFA (plik PDF z dodaną warstwą tekstową umożliwiającą np. przeszukiwanie dokumentu) z załadowanego zdjęcia lub pliku PDF.
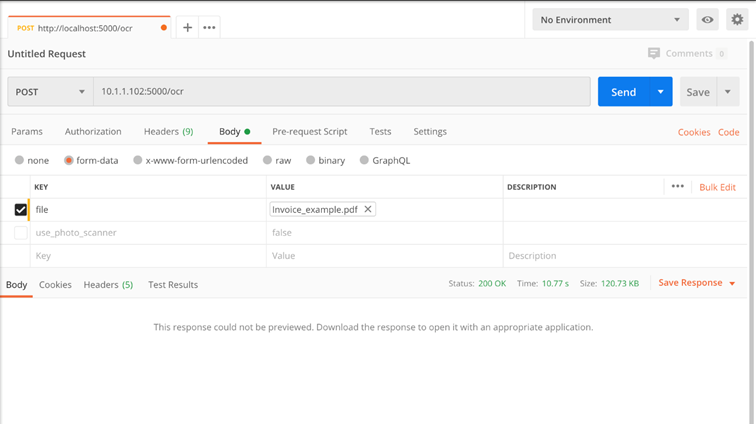
Metoda: ./ocr
Parametry wejściowe:
- file – plik jpg/jpeg, png, tif, pdf
- use_photo_scanner – domyślnie true. W przypadku załadowania zdjęcia dokumentu zrobionego smartfonem, system stosuje zestaw filtrów (zwiększanie kontrastu, usuwanie cieni, etc.), które zwiększają skuteczność OCR
Zwraca:
· file – plik PDFA (przeszukiwalny PDF)
Przykład:
Text classification
Celem tej grupy usług jest określenie dowolnej klasy (typu dokumentu, kategorii, właściciela, numeru konta etc.) na podstawie analizy tekstu na dokumencie.
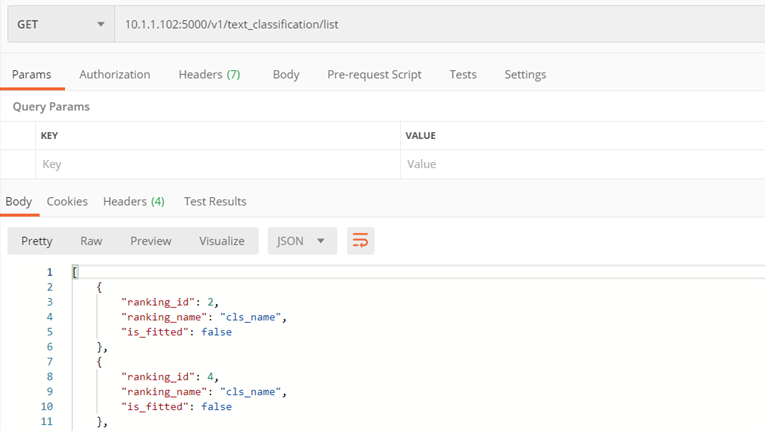
Metoda ./v1/text_classification/list
Celem metody jest zwrócenie listy klasyfikatorów zapisanych na serwerze
Parametry wejściowe:
- brak
Zwraca:
- Lista dostępnych klasyfikatorów, zawierającą
- ranking_id – id klasyfikatora,
- ranking_name – nazwa klasyfikatora,
- is_fitted – czy jest nauczony
Przykład:
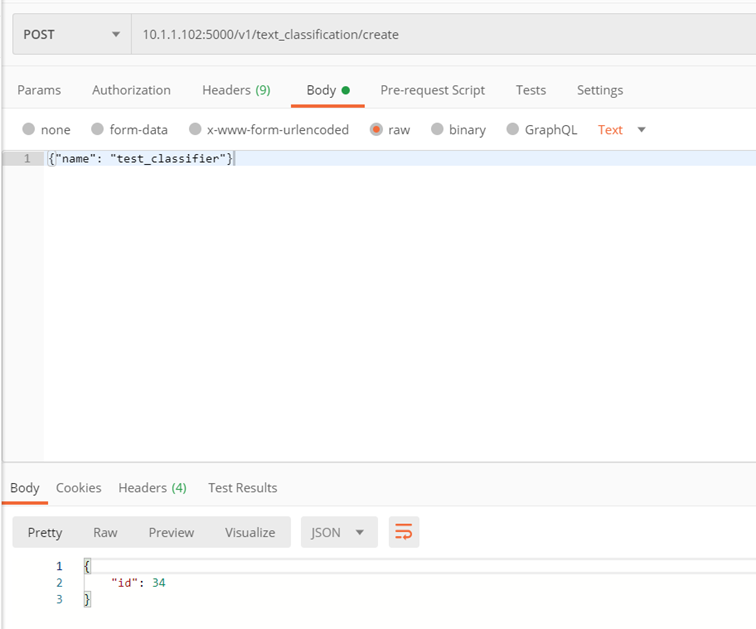
Metoda: ./v1/text_classification/create Celem metody jest utworzenie klasyfikatora.
Parametry wejściowe:
- name – nazwa klasyfikatora
Zwraca:
- classifer_id – id utworzonego klasyfikatora
Przykład:
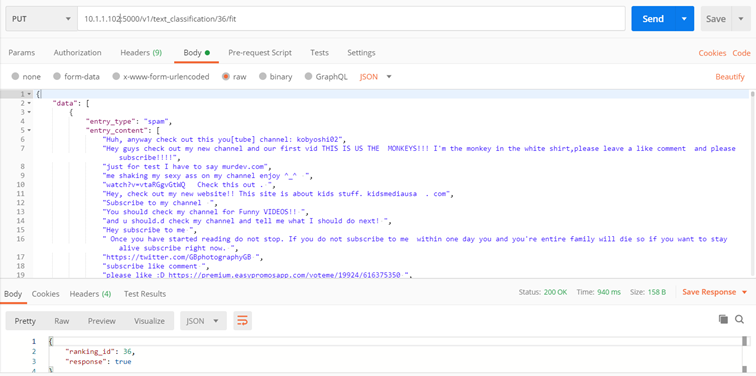
Metoda: ./v1/text_classification/{classifier_id}/fit
Celem metody jest wyuczenie klasyfikatora
Parametry wejściowe:
- classifier_id – id klasyfikatora
- kolekcja (kolekcja tekstów uczących)
- entry_type – nazwa klasy (np. faktura, CV, pismo etc.)
- entry_content – blok tekstowy (kompletna treść dokumentu, wszystko co zwraca OCR)
Zwraca:
- kod 200 – pozytywne wyuczenie modelu
- kod 422 – błąd (zwracany jest komunikat błędu)
Przykład:
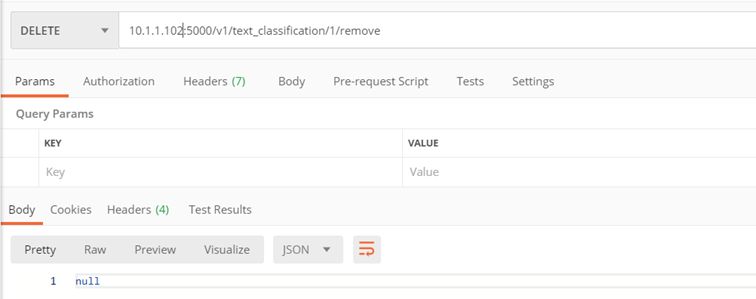
Metoda: ./v1/text_classification/{classifier_id}/remove
Celem metody jest usunięcie klasyfikatora
Parametry wejściowe:
- classifier_id – id klasyfikatora, który chcemy usunąć z serwera
Zwraca:
- kod 200 – pozytywne usunięcie modelu
- kod 422 – błąd (zwracany jest komunikat błędu)
Przykład:
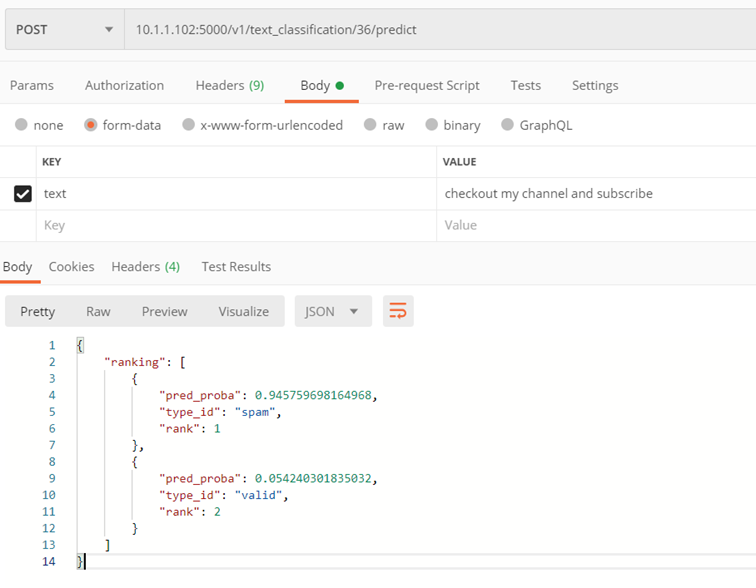
Metoda: ./v1/text_classification/{classifier_id}/predict
Celem metody jest wykonanie klasyfikacji tekstu dla danego klasyfikatora
Parametry wejściowe:
- classifier_id– id klasyfikatora, w oparciu o który ma być wykonana klasyfikacja
- text – tekst, który ma zostać sklasyfikowany
- file – plik PDFA, który ma zostać sklasyfikowany
Uwagi:
można podać albo plik (file) albo tekst.
Zwraca:
- Uszeregowane według prawdopodobieństwa kolekcja klas dla przekazanego tekstu:
- pred_proba – prawdopodobieństwo
- type_id – klasa
- rank – pozycja w rankingu
Przykład:
Data capture
Celem tej grupy usług jest przechwycenie danych z badanego dokumentu. Dla przykładu dla faktur są to : numer faktury, numery nip, daty, numer konta, stawki i kwoty VAT, tabelka z pozycjami dokumentu
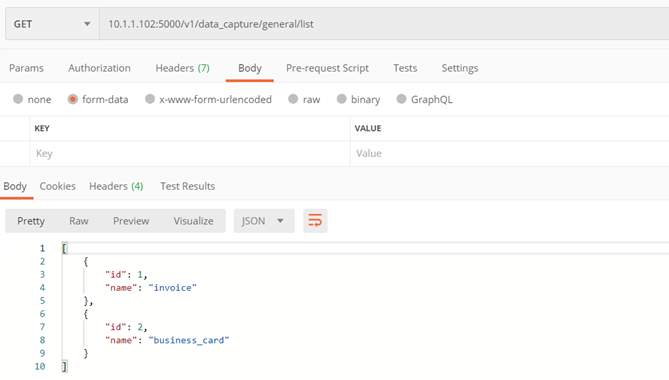
Metoda ./v1/data_capture/general/list
Zwraca dostępne aktualnie modele ogólne
Parametry:
- Brak
Zwraca:
- Lista dostępnych modeli ogólnych z ich id
Przykład:
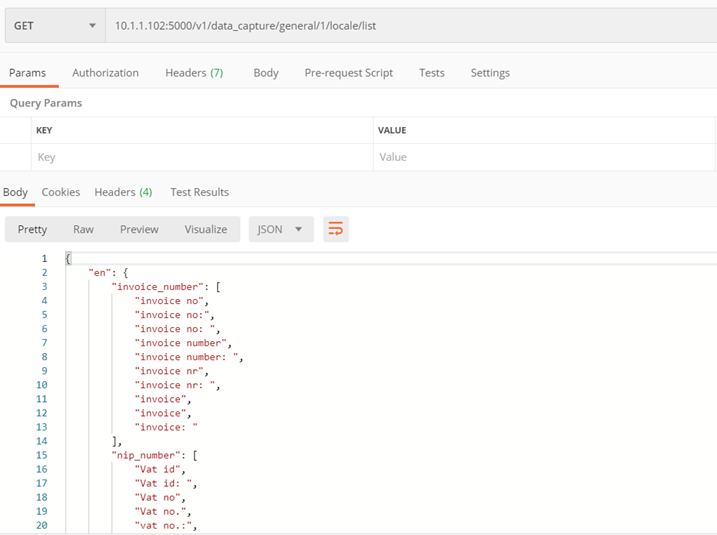
Metoda ./v1/data_capture/general/{model_id}/locale/list
Celem metody jest zwrócenie wspieranych języków i dostępnych w nich prefiksów
Metoda tylko dla modelu ogólnego faktur – nr 1
Parametry:
- model_id – id modelu, którego prefiksy zwróci metoda
Zwraca:
- Lista słowników z informacją na temat wspieranych języków oraz dostępnych w nich prefiksów
Przykład:
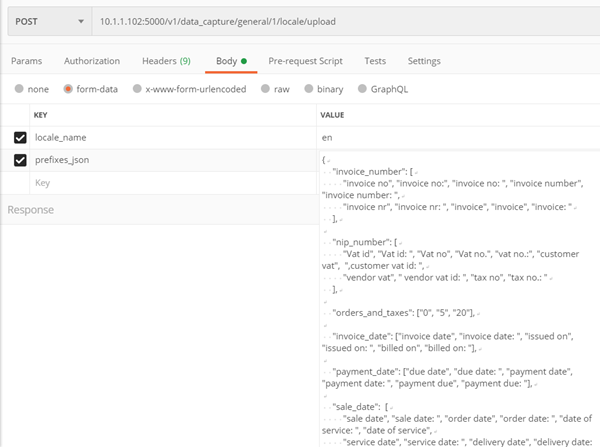
Metoda ./v1/data_capture/general/1/locale/upload
Umożliwia dodania własnego wspieranego języka poprzez podanie prefiksów
Metoda tylko dla modelu ogólnego faktur – nr 1
Parametry:
- locale_name – nazwa local’a (języka), którego prefiksy chcemy przekazać, musi być to jeden z: af, ar, bg, bn, ca, cs, cy, da, de, el, en, es, et, fa, fi, fr, gu, he, hi, hr, hu, id, it, ja, kn, ko, lt, lv, mk, ml, mr, ne, nl, no, pa, pl, pt, ro, ru, sk, sl, so, sq, sv, sw, ta, te, th, tl, tr, uk, ur, vi, zh-cn, zh-tw
- prefixes_json – słownik, zawierający dla każdego z kluczy (invoice_number, nip_number, orders_and_taxes (vat_rates), invoice_date, payment_date, sale_date) listę prefiksów występujących w danym języku
Zwraca:
- Kod 200 – pozytywne nauczenie modelu
- Kod 400 – błąd
Przykład:
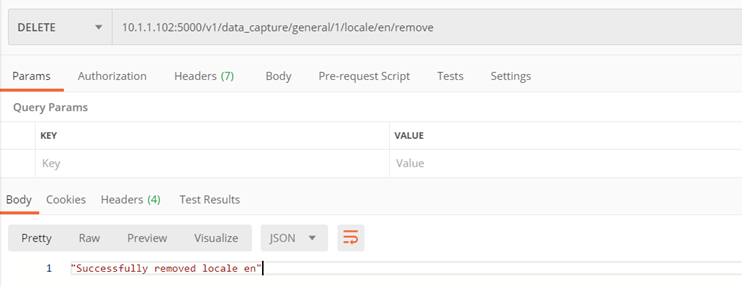
Metoda ./v1/data_capture/general/{model_id}/locale/{locale_name}/remove
Usunięcie wspieranego języka
Metoda tylko dla modelu ogólnego faktur – nr 1
Parametry:
- locale_name – nazwa języka do usunięcia, np. ‘en’
- model_id – id modelu, z którego usuwamy locale
Zwraca:
- Kod 200 – pomyślne usunięcie
Przykład:
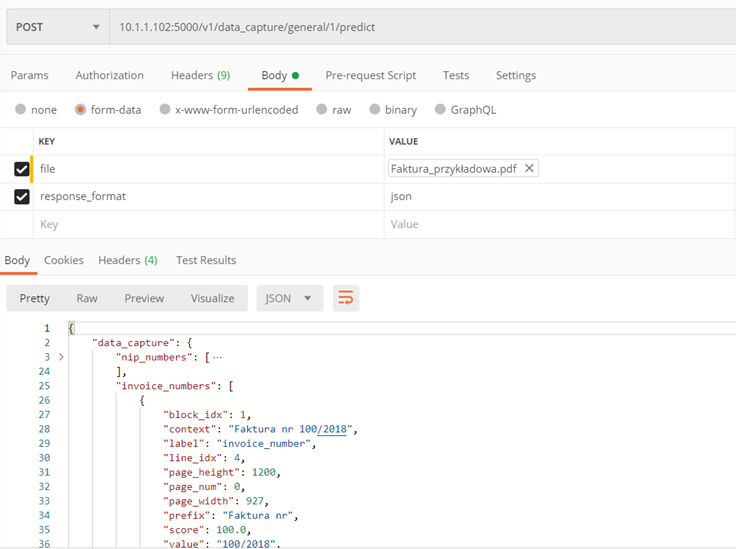
Metoda ./v1/data_capture/general/{model_id}/predict
Zwrócenie informacji zawartych w tekście przesłanego pliku.
Parametry:
- model_id – id modelu, za pomocą którego wykonamy predykcję
- file – przeszukiwalny plik PDF
- locale (opcjonalnie) – nazwa języka dokumentu. Jeśli nie podany, program sam określi język na podstawie tekstu i użyje odpowiadające mu prefiksy
- response_format (opcjonalnie) – format, w którym zwrócone zostaną informacje, do wyboru: brak, xml, json
Zwraca:
- Uzyskane z tekstu informacje w formacie json lub xml
Przykład:
File splitter
Usługa pozwalająca na rozdzielanie dokumentów zeskanowanych razem do jednego pliku do osobnych plików, gdzie każdy plik odpowiada osobnemu dokumentowi. Posiada możliwość nauczenia dowolnej ilości własnych splitterów do własnego typu dokumentów
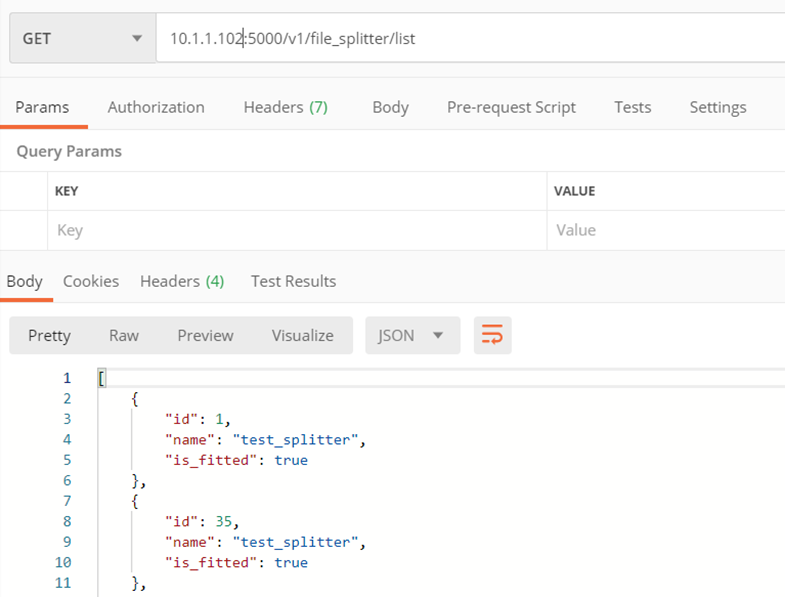
Metoda ./v1/file_splitter/list
Zwraca listę splitterów (modeli)
Parametry:
- brak
Zwraca:
- Listę dostępnych splitterów, zawierającą dla każdego: jego nazwę, id oraz informację, czy jest nauczony
Przykład:
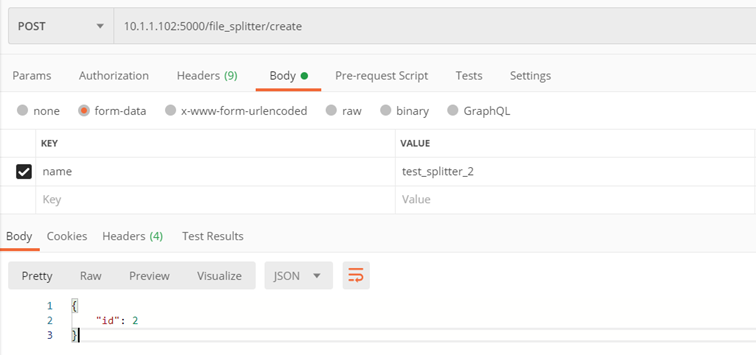
Metoda ./v1/file_splitter/create
Tworzenie własnego splittera
Parametry:
- name – nazwa splittera
Zwraca:
- Id utworzonego splittera
Przykład:
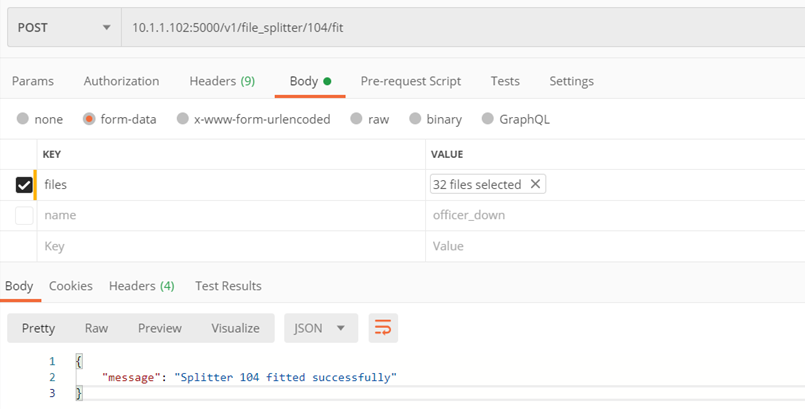
Metoda ./v1/file_splitter/{splitter_id}/fit
Nauczenie splittera rozdzielania dokumentów
Parametry:
- splitter_id – id splittera który chcemy nauczyć
- files – lista plików, na podstawie których splitter nauczy się rozdzielać dokumenty
Zwraca:
- Kod 200 – poprawnie nauczony splitter
- Kod 400 – błąd
Przykład:
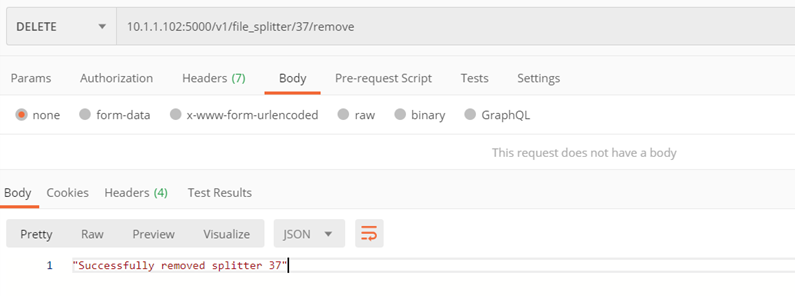
Metoda ./v1/file_splitter/{splitter_id}/remove
Usunięcie wybranego splittera
Parametry:
- splitter_id – id splittera do usunięcia
Zwraca:
- Kod 200 – pozytywne usunięcie
- Kod 400 – błąd
Przykład:
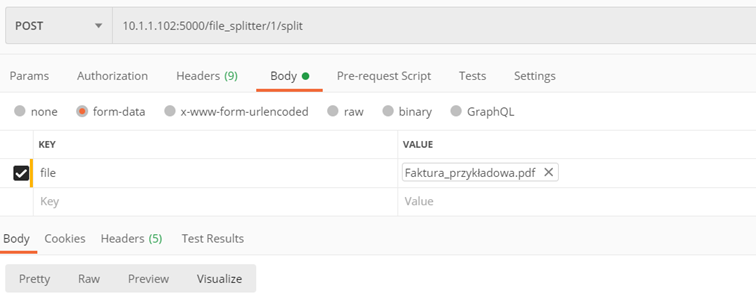
Metoda ./v1/file_splitter/{splitter_id}/split
Rozdzielenie pliku z wieloma dokumentami do pojedynczych
Parametry:
- splitter_id – id splittera, którego używamy do rozdziału pliku
- file – przeszukiwalny plik PDF, który chcemy rozdzielić
Zwraca:
- Plik zip z zapisanymi osobnymi plikami pdf
Przykład: